About TravelSurveyTools
The travelSurveyTools package provides tools for R users
to aid use of data from household travel surveys. Some possible uses
include creating custom cross tabs, labeling data, and calculating trip
rates.
Data Assumptions
travelSurveyTools assumes the the data have the
structure shown below. If this does not reflect the structure of your
data
hts_data
hts_data is a list of five core tables:
hh
Household dataset
- hh_id: 8 digit household ID
- survey variables asked on a household level
- hh_weight: household weight
person
Person dataset
- hh_id: 8 digit household ID
- person_id: 10 digit person ID
- survey variables asked on a person level
- person_weight: person weight
day
Day dataset
- hh_id: 8 digit household ID
- person_id: 10 digit person ID
- day_id: 12 digit day ID
- survey variable asked on a day level
- day_weight: day weight
Codebook
In addition to data from the household travel survey. The codebook is also required. The codebook is assumed to be in two parts:
variable_list
A dataset containing information about all variables existing in the hh, person, day, trip, and vehicle tables. The variables are as follows:
- variable: Name of the variable
- is_checkbox: The variable is a ‘Select all that Apply’ question
- hh: The variable exists in the hh table
- person: The variable exists in the person table
- day: The variable exists in the day table
- trip: The variable exists in the trip table
- vehicle: The variable exists in the vehicle table
- location: The variable exists in the location table
- data_type: Data type of the variable
- description: A description of the variable
- logic: Conditions where the variable should have a value
- shared_name: the shared name of checkbox variable or the variable name for non-checkbox variables
value_labels
A dataset containing the values for all variables found in variable_list The variables are as follows:
- variable: Name of the variable
- value: The numeric value of the variable
- label: What the numeric value of the variable represents
- label_value: value concatenated with the label (e.g., 11 85 or older)
- val_order: order for each variable label to appear in
Using travelSurveyTools
Prepping the Data
In order to create summaries of our data we first need to prepare our
data. We can do this by using hts_prep_data. This will
return a categorical (cat) and numeric (num) (if applicable) prepped
data table that can be used to create summaries.
## Warning: package 'data.table' was built under R version 4.3.2## Warning: package 'srvyr' was built under R version 4.3.2
# Load data
data("test_data")
data("variable_list")
data("value_labels")
DT = hts_prep_data(summarize_var = 'speed_mph',
variables_dt = variable_list,
data = test_data)Numeric variables will be automatically binned in
hts_prep_data to create categorical summaries. Here we can
make a categorical summary of a numeric variable using
hts_summary.
speed_cat_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'speed_mph',
summarize_by = NULL,
summarize_vartype = 'categorical',
weighted = FALSE)
speed_cat_summary$summary## $unwtd
## Key: <speed_mph>
## speed_mph count prop
## <fctr> <int> <num>
## 1: 1 or less 720 0.04902962
## 2: 1-9 6825 0.46475996
## 3: 9-17 3494 0.23792986
## 4: 17-25 1995 0.13585291
## 5: 25-33 868 0.05910793
## 6: 33-41 414 0.02819203
## 7: 41 or more 369 0.02512768Additionally, for numeric variables we can create numeric summaries.
speed_num_summary = hts_summary(prepped_dt = DT$num,
summarize_var = 'speed_mph',
summarize_by = NULL,
summarize_vartype = 'numeric',
weighted = FALSE)
speed_num_summary$summary## $unwtd
## count min max mean median
## <int> <num> <num> <num> <num>
## 1: 14685 0 112.9918 11.83172 8.63421Using Weighted Data
Additionally, we can use weighted data by setting
weighted = TRUE and specifying the name of the weight to be
used (wtname).
speed_cat_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'speed_mph',
summarize_by = NULL,
summarize_vartype = 'categorical',
weighted = TRUE,
wtname = 'trip_weight')
speed_cat_summary$summary## $unwtd
## Key: <speed_mph>
## speed_mph count prop
## <fctr> <int> <num>
## 1: 1 or less 720 0.04902962
## 2: 1-9 6825 0.46475996
## 3: 9-17 3494 0.23792986
## 4: 17-25 1995 0.13585291
## 5: 25-33 868 0.05910793
## 6: 33-41 414 0.02819203
## 7: 41 or more 369 0.02512768
##
## $wtd
## speed_mph count prop est
## <fctr> <int> <num> <int>
## 1: 1 or less 720 0.05017047 370818
## 2: 1-9 6825 0.46380595 3428064
## 3: 9-17 3494 0.23966211 1771381
## 4: 17-25 1995 0.13432492 992817
## 5: 25-33 868 0.05766713 426227
## 6: 33-41 414 0.02801374 207054
## 7: 41 or more 369 0.02635567 194799
##
## $weight_name
## [1] "trip_weight"Calculating Standard Errors
Additionally, by specifying se = TRUE we can calculate
standard errors.
speed_cat_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'speed_mph',
summarize_by = NULL,
summarize_vartype = 'categorical',
weighted = TRUE,
wtname = 'trip_weight',
se = TRUE)
speed_cat_summary$summary## $unwtd
## Key: <speed_mph>
## speed_mph count prop
## <fctr> <int> <num>
## 1: 1 or less 720 0.04902962
## 2: 1-9 6825 0.46475996
## 3: 9-17 3494 0.23792986
## 4: 17-25 1995 0.13585291
## 5: 25-33 868 0.05910793
## 6: 33-41 414 0.02819203
## 7: 41 or more 369 0.02512768
##
## $wtd
## speed_mph count prop prop_se est est_se
## <fctr> <int> <num> <num> <num> <num>
## 1: 1 or less 720 0.05017047 0.002079083 370818 15469.78
## 2: 1-9 6825 0.46380595 0.004737688 3428064 38508.63
## 3: 9-17 3494 0.23966211 0.004069031 1771381 31295.73
## 4: 17-25 1995 0.13432492 0.003228756 992817 24287.87
## 5: 25-33 868 0.05766713 0.002192303 426227 16305.76
## 6: 33-41 414 0.02801374 0.001560836 207054 11574.44
## 7: 41 or more 369 0.02635567 0.001548421 194799 11492.05
##
## $weight_name
## [1] "trip_weight"Summarizing Two Variables
If we want to summarize a variable by another variable (e.g., mode
type by a person’s race, mode_type by a person’s ethnicity, income by
study year) we can use the summarize_by argument.
DT = hts_prep_data(summarize_var = 'mode_type',
summarize_by = 'race',
variables_dt = variable_list,
data = test_data)
mode_by_race_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'mode_type',
summarize_by = 'race',
summarize_vartype = 'categorical',
weighted = TRUE,
wtname = 'trip_weight',
se = TRUE)
mode_by_race_summary$summary## $unwtd
## Key: <race>
## race mode_type count prop
## <fctr> <int> <int> <num>
## 1: African American or Black 1 146 0.3753213368
## 2: African American or Black 3 4 0.0102827763
## 3: African American or Black 4 1 0.0025706941
## 4: African American or Black 6 1 0.0025706941
## 5: African American or Black 7 1 0.0025706941
## 6: African American or Black 8 180 0.4627249357
## 7: African American or Black 11 3 0.0077120823
## 8: African American or Black 13 53 0.1362467866
## 9: American Indian or Alaska Native 1 7 0.1521739130
## 10: American Indian or Alaska Native 8 36 0.7826086957
## 11: American Indian or Alaska Native 13 3 0.0652173913
## 12: Asian 1 689 0.3123300091
## 13: Asian 2 32 0.0145058930
## 14: Asian 4 2 0.0009066183
## 15: Asian 5 2 0.0009066183
## 16: Asian 6 12 0.0054397099
## 17: Asian 7 41 0.0185856754
## 18: Asian 8 1249 0.5661831369
## 19: Asian 11 30 0.0135992747
## 20: Asian 12 1 0.0004533092
## 21: Asian 13 141 0.0639165911
## 22: Asian 14 7 0.0031731641
## 23: Native Hawaiian or other Pacific Islander 1 29 0.4531250000
## 24: Native Hawaiian or other Pacific Islander 6 1 0.0156250000
## 25: Native Hawaiian or other Pacific Islander 8 34 0.5312500000
## 26: White 1 2934 0.3034753827
## 27: White 2 242 0.0250310302
## 28: White 3 3 0.0003103020
## 29: White 4 26 0.0026892842
## 30: White 5 3 0.0003103020
## 31: White 6 36 0.0037236243
## 32: White 7 59 0.0061026065
## 33: White 8 5765 0.5962970625
## 34: White 10 14 0.0014480761
## 35: White 11 37 0.0038270583
## 36: White 12 8 0.0008274721
## 37: White 13 516 0.0533719487
## 38: White 14 25 0.0025858502
## 39: Two or more 1 243 0.4111675127
## 40: Two or more 2 10 0.0169204738
## 41: Two or more 6 6 0.0101522843
## 42: Two or more 8 270 0.4568527919
## 43: Two or more 11 2 0.0033840948
## 44: Two or more 13 60 0.1015228426
## 45: Other race 1 51 0.2931034483
## 46: Other race 5 1 0.0057471264
## 47: Other race 6 1 0.0057471264
## 48: Other race 8 104 0.5977011494
## 49: Other race 11 3 0.0172413793
## 50: Other race 13 13 0.0747126437
## 51: Other race 14 1 0.0057471264
## 52: Prefer not to answer 1 358 0.3455598456
## 53: Prefer not to answer 2 39 0.0376447876
## 54: Prefer not to answer 3 3 0.0028957529
## 55: Prefer not to answer 4 5 0.0048262548
## 56: Prefer not to answer 5 1 0.0009652510
## 57: Prefer not to answer 6 6 0.0057915058
## 58: Prefer not to answer 7 2 0.0019305019
## 59: Prefer not to answer 8 548 0.5289575290
## 60: Prefer not to answer 11 4 0.0038610039
## 61: Prefer not to answer 13 69 0.0666023166
## 62: Prefer not to answer 14 1 0.0009652510
## race mode_type count prop
##
## $wtd
## race mode_type count prop
## <fctr> <int> <int> <num>
## 1: African American or Black 1 146 0.3905712667
## 2: African American or Black 3 4 0.0126026621
## 3: African American or Black 4 1 0.0023516203
## 4: African American or Black 6 1 0.0043795768
## 5: African American or Black 7 1 0.0023566776
## 6: African American or Black 8 180 0.4284500546
## 7: African American or Black 11 3 0.0044149775
## 8: African American or Black 13 53 0.1548731642
## 9: American Indian or Alaska Native 1 7 0.1450820029
## 10: American Indian or Alaska Native 8 36 0.7467699134
## 11: American Indian or Alaska Native 13 3 0.1081480837
## 12: Asian 1 689 0.3051702848
## 13: Asian 2 32 0.0166409377
## 14: Asian 4 2 0.0007410683
## 15: Asian 5 2 0.0009939142
## 16: Asian 6 12 0.0064949215
## 17: Asian 7 41 0.0190691777
## 18: Asian 8 1249 0.5658590003
## 19: Asian 11 30 0.0161453597
## 20: Asian 12 1 0.0002583625
## 21: Asian 13 141 0.0651487332
## 22: Asian 14 7 0.0034782401
## 23: Native Hawaiian or other Pacific Islander 1 29 0.4204865855
## 24: Native Hawaiian or other Pacific Islander 6 1 0.0239513996
## 25: Native Hawaiian or other Pacific Islander 8 34 0.5555620149
## 26: White 1 2934 0.3041972747
## 27: White 2 242 0.0243721513
## 28: White 3 3 0.0002999808
## 29: White 4 26 0.0023771364
## 30: White 5 3 0.0003299170
## 31: White 6 36 0.0037343793
## 32: White 7 59 0.0062000853
## 33: White 8 5765 0.5978921238
## 34: White 10 14 0.0020777749
## 35: White 11 37 0.0035603367
## 36: White 12 8 0.0007298226
## 37: White 13 516 0.0518479582
## 38: White 14 25 0.0023810590
## 39: Two or more 1 243 0.4165906782
## 40: Two or more 2 10 0.0142847408
## 41: Two or more 6 6 0.0099882853
## 42: Two or more 8 270 0.4517833211
## 43: Two or more 11 2 0.0033521438
## 44: Two or more 13 60 0.1040008307
## 45: Other race 1 51 0.2979641649
## 46: Other race 5 1 0.0100404948
## 47: Other race 6 1 0.0073445387
## 48: Other race 8 104 0.5797193099
## 49: Other race 11 3 0.0183946303
## 50: Other race 13 13 0.0852055250
## 51: Other race 14 1 0.0013313363
## 52: Prefer not to answer 1 358 0.3525751627
## 53: Prefer not to answer 2 39 0.0415813644
## 54: Prefer not to answer 3 3 0.0038718201
## 55: Prefer not to answer 4 5 0.0039204752
## 56: Prefer not to answer 5 1 0.0004790652
## 57: Prefer not to answer 6 6 0.0046241022
## 58: Prefer not to answer 7 2 0.0011302945
## 59: Prefer not to answer 8 548 0.5225422644
## 60: Prefer not to answer 11 4 0.0023429284
## 61: Prefer not to answer 13 69 0.0657105323
## 62: Prefer not to answer 14 1 0.0012219906
## race mode_type count prop
## prop_se est est_se
## <num> <num> <num>
## 1: 0.0282906311 77230 7202.7558
## 2: 0.0066885378 2492 1331.4537
## 3: 0.0023500849 465 465.0000
## 4: 0.0043678202 866 866.0000
## 5: 0.0023551269 466 466.0000
## 6: 0.0284115856 84720 7290.3594
## 7: 0.0026365365 873 521.1549
## 8: 0.0211938329 30624 4566.8926
## 9: 0.0583277190 3335 1444.1155
## 10: 0.0758001371 17166 3291.4253
## 11: 0.0588410966 2486 1452.3590
## 12: 0.0112751847 331909 14406.1991
## 13: 0.0031684441 18099 3472.2550
## 14: 0.0005374246 806 584.5719
## 15: 0.0007866950 1081 856.0153
## 16: 0.0020499103 7064 2236.5492
## 17: 0.0033706757 20740 3697.6048
## 18: 0.0121719999 615439 19446.9203
## 19: 0.0031535242 17560 3455.7525
## 20: 0.0002583829 281 281.0000
## 21: 0.0060809393 70857 6815.9100
## 22: 0.0015826609 3783 1724.5385
## 23: 0.0704335805 14466 3130.6398
## 24: 0.0236229664 824 824.0000
## 25: 0.0710921620 19113 3722.8271
## 26: 0.0054007054 1473423 28836.5035
## 27: 0.0017956576 118050 8747.8272
## 28: 0.0002038448 1453 987.4254
## 29: 0.0005430718 11514 2631.4671
## 30: 0.0002123764 1598 1028.7568
## 31: 0.0007110315 18088 3447.0041
## 32: 0.0009039482 30031 4384.2723
## 33: 0.0057494999 2895976 36610.7988
## 34: 0.0005799747 10064 2811.2886
## 35: 0.0006760499 17245 3276.7898
## 36: 0.0003057402 3535 1481.0996
## 37: 0.0025833876 251133 12671.2132
## 38: 0.0005582162 11533 2705.1327
## 39: 0.0231395983 128377 9252.3454
## 40: 0.0057348621 4402 1780.3574
## 41: 0.0043327331 3078 1340.5366
## 42: 0.0233781385 139222 9656.1625
## 43: 0.0023683811 1033 730.6294
## 44: 0.0146015906 32049 4757.0427
## 45: 0.0401920453 26857 4365.3044
## 46: 0.0099774410 905 905.0000
## 47: 0.0073183153 662 662.0000
## 48: 0.0429156650 52253 5852.2429
## 49: 0.0107967923 1658 980.6406
## 50: 0.0239410741 7680 2253.0918
## 51: 0.0013345935 120 120.0000
## 52: 0.0170273904 188407 11212.9544
## 53: 0.0072538913 22220 3958.7011
## 54: 0.0022959360 2069 1229.3224
## 55: 0.0019000907 2095 1016.4577
## 56: 0.0004791561 256 256.0000
## 57: 0.0023053628 2471 1234.3289
## 58: 0.0010238556 604 547.2946
## 59: 0.0177823597 279233 13535.4928
## 60: 0.0016165519 1252 864.6572
## 61: 0.0087882893 35114 4848.2740
## 62: 0.0012213144 653 653.0000
## prop_se est est_se
##
## $weight_name
## [1] "trip_weight"If we want to summarize a select all that apply variable, we can set
summarize_vartype to checkbox.
DT = hts_prep_data(summarize_var = 'race',
summarize_by = 'mode_type',
variables_dt = variable_list,
data = test_data)
mode_by_race_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'race',
summarize_by = 'mode_type',
summarize_vartype = 'checkbox',
weighted = TRUE,
wtname = 'trip_weight',
se = TRUE)
mode_by_race_summary$summary## $unwtd
## Key: <mode_type>
## mode_type race count prop
## <int> <fctr> <int> <num>
## 1: 1 African American or Black 190 0.039840637
## 2: 1 American Indian or Alaska Native 100 0.020968757
## 3: 1 Asian 808 0.169427553
## 4: 1 Native Hawaiian or other Pacific Islander 34 0.007129377
## 5: 1 White 3174 0.665548333
## 6: 1 Other race 105 0.022017194
## 7: 1 Prefer not to answer 358 0.075068148
## 8: 2 Asian 38 0.114114114
## 9: 2 White 252 0.756756757
## 10: 2 Other race 4 0.012012012
## 11: 2 Prefer not to answer 39 0.117117117
## 12: 3 African American or Black 4 0.400000000
## 13: 3 White 3 0.300000000
## 14: 3 Prefer not to answer 3 0.300000000
## 15: 4 African American or Black 1 0.029411765
## 16: 4 Asian 2 0.058823529
## 17: 4 White 26 0.764705882
## 18: 4 Prefer not to answer 5 0.147058824
## 19: 5 Asian 2 0.285714286
## 20: 5 White 3 0.428571429
## 21: 5 Other race 1 0.142857143
## 22: 5 Prefer not to answer 1 0.142857143
## 23: 6 African American or Black 1 0.014492754
## 24: 6 American Indian or Alaska Native 1 0.014492754
## 25: 6 Asian 15 0.217391304
## 26: 6 Native Hawaiian or other Pacific Islander 1 0.014492754
## 27: 6 White 42 0.608695652
## 28: 6 Other race 3 0.043478261
## 29: 6 Prefer not to answer 6 0.086956522
## 30: 7 African American or Black 1 0.009708738
## 31: 7 Asian 41 0.398058252
## 32: 7 White 59 0.572815534
## 33: 7 Prefer not to answer 2 0.019417476
## 34: 8 African American or Black 202 0.023882715
## 35: 8 American Indian or Alaska Native 92 0.010877276
## 36: 8 Asian 1405 0.166114921
## 37: 8 Native Hawaiian or other Pacific Islander 76 0.008985576
## 38: 8 White 5991 0.708323481
## 39: 8 Other race 144 0.017025301
## 40: 8 Prefer not to answer 548 0.064790731
## 41: 10 White 14 1.000000000
## 42: 11 African American or Black 5 0.060240964
## 43: 11 American Indian or Alaska Native 2 0.024096386
## 44: 11 Asian 30 0.361445783
## 45: 11 White 39 0.469879518
## 46: 11 Other race 3 0.036144578
## 47: 11 Prefer not to answer 4 0.048192771
## 48: 12 Asian 1 0.111111111
## 49: 12 White 8 0.888888889
## 50: 13 African American or Black 70 0.074706510
## 51: 13 American Indian or Alaska Native 40 0.042689434
## 52: 13 Asian 153 0.163287086
## 53: 13 White 576 0.614727855
## 54: 13 Other race 29 0.030949840
## 55: 13 Prefer not to answer 69 0.073639274
## 56: 14 Asian 7 0.205882353
## 57: 14 White 25 0.735294118
## 58: 14 Other race 1 0.029411765
## 59: 14 Prefer not to answer 1 0.029411765
## mode_type race count prop
##
## $wtd
## mode_type race count prop
## <int> <fctr> <int> <num>
## 1: 1 African American or Black 190 0.040013489
## 2: 1 American Indian or Alaska Native 100 0.021076910
## 3: 1 Asian 808 0.166476198
## 4: 1 Native Hawaiian or other Pacific Islander 34 0.006831490
## 5: 1 White 3174 0.666577157
## 6: 1 Other race 105 0.020586062
## 7: 1 Prefer not to answer 358 0.078438695
## 8: 2 Asian 38 0.126072990
## 9: 2 White 252 0.732486705
## 10: 2 Other race 4 0.008524104
## 11: 2 Prefer not to answer 39 0.132916201
## 12: 3 African American or Black 4 0.414366478
## 13: 3 White 3 0.241602927
## 14: 3 Prefer not to answer 3 0.344030595
## 15: 4 African American or Black 1 0.031250000
## 16: 4 Asian 2 0.054166667
## 17: 4 White 26 0.773790323
## 18: 4 Prefer not to answer 5 0.140793011
## 19: 5 Asian 2 0.281510417
## 20: 5 White 3 0.416145833
## 21: 5 Other race 1 0.235677083
## 22: 5 Prefer not to answer 1 0.066666667
## 23: 6 African American or Black 1 0.023968337
## 24: 6 American Indian or Alaska Native 1 0.013589438
## 25: 6 Asian 15 0.245800006
## 26: 6 Native Hawaiian or other Pacific Islander 1 0.022805901
## 27: 6 White 42 0.585812737
## 28: 6 Other race 3 0.039633556
## 29: 6 Prefer not to answer 6 0.068390025
## 30: 7 African American or Black 1 0.008989024
## 31: 7 Asian 41 0.400069443
## 32: 7 White 59 0.579290523
## 33: 7 Prefer not to answer 2 0.011651010
## 34: 8 African American or Black 202 0.022452608
## 35: 8 American Indian or Alaska Native 92 0.011322711
## 36: 8 Asian 1405 0.163974235
## 37: 8 Native Hawaiian or other Pacific Islander 76 0.009421685
## 38: 8 White 5991 0.709942163
## 39: 8 Other race 144 0.017067744
## 40: 8 Prefer not to answer 548 0.065818854
## 41: 10 White 14 1.000000000
## 42: 11 African American or Black 5 0.045721688
## 43: 11 American Indian or Alaska Native 2 0.024779907
## 44: 11 Asian 30 0.421234438
## 45: 11 White 39 0.438458032
## 46: 11 Other race 3 0.039772591
## 47: 11 Prefer not to answer 4 0.030033344
## 48: 12 Asian 1 0.073637317
## 49: 12 White 8 0.926362683
## 50: 13 African American or Black 70 0.080582483
## 51: 13 American Indian or Alaska Native 40 0.045759209
## 52: 13 Asian 153 0.162498668
## 53: 13 White 576 0.603323604
## 54: 13 Other race 29 0.033025119
## 55: 13 Prefer not to answer 69 0.074810917
## 56: 14 Asian 7 0.235129592
## 57: 14 White 25 0.716825160
## 58: 14 Other race 1 0.007458512
## 59: 14 Prefer not to answer 1 0.040586736
## mode_type race count prop
## prop_se est est_se
## <num> <num> <num>
## 1: 0.003480119 96111 7975.0422
## 2: 0.002542819 50626 5768.3288
## 3: 0.006568278 399870 16186.7733
## 4: 0.001479919 16409 3332.9169
## 5: 0.007787283 1601095 32330.8859
## 6: 0.002488825 49447 5643.0323
## 7: 0.004825536 188407 11307.9346
## 8: 0.021673410 21076 3786.3301
## 9: 0.027934367 122452 8973.4484
## 10: 0.005832891 1425 953.4106
## 11: 0.022521537 22220 3962.3508
## 12: 0.169167822 2492 1331.5545
## 13: 0.144247992 1453 987.4602
## 14: 0.164240660 2069 1229.3905
## 15: 0.030872908 465 465.0000
## 16: 0.038590666 806 584.5878
## 17: 0.076849954 11514 2632.9105
## 18: 0.064158837 2095 1016.5575
## 19: 0.189992252 1081 856.0307
## 20: 0.208480521 1598 1028.8007
## 21: 0.198601443 905 905.0000
## 22: 0.068252522 256 256.0000
## 23: 0.025775549 866 866.0000
## 24: 0.014784403 491 491.0000
## 25: 0.063926195 8881 2490.2346
## 26: 0.024557643 824 824.0000
## 27: 0.069091983 21166 3700.9843
## 28: 0.026555002 1432 893.3361
## 29: 0.036046741 2471 1234.4411
## 30: 0.008964261 466 466.0000
## 31: 0.054902198 20740 3701.0089
## 32: 0.055185761 30031 4390.3553
## 33: 0.010514366 604 547.2982
## 34: 0.001873969 95254 7769.5082
## 35: 0.001398626 48036 5771.9859
## 36: 0.004762250 695652 21306.4777
## 37: 0.001276091 39971 5261.1217
## 38: 0.005617560 3011892 43812.4684
## 39: 0.001666708 72409 6895.2034
## 40: 0.003230268 279233 13708.1607
## 41: 0.000000000 10064 2812.2928
## 42: 0.022381920 1906 897.4773
## 43: 0.018255748 1033 730.6515
## 44: 0.063430268 17560 3458.3451
## 45: 0.063068208 18278 3359.7885
## 46: 0.024280629 1658 980.6957
## 47: 0.021499876 1252 864.6859
## 48: 0.073962514 281 281.0000
## 49: 0.073962514 3535 1481.3100
## 50: 0.011247084 37823 5066.8771
## 51: 0.008727320 21478 3852.7941
## 52: 0.015009542 76272 7108.1562
## 53: 0.018695102 283182 13670.8385
## 54: 0.007444624 15501 3261.5427
## 55: 0.010821499 35114 4855.8112
## 56: 0.091554896 3783 1724.7373
## 57: 0.095130908 11533 2706.5373
## 58: 0.007557031 120 120.0000
## 59: 0.039773659 653 653.0000
## prop_se est est_se
##
## $weight_name
## [1] "trip_weight"summarize_by can be used with an unlimited amount of
variables. To use more than one summarize_by variable pass
a list to the argument.
DT = hts_prep_data(summarize_var = 'mode_type',
summarize_by = c('race', 'ethnicity'),
variables_dt = variable_list,
data = list('hh' = hh,
'person' = person,
'day' = day,
'trip' = trip,
'vehicle' = vehicle))
mode_by_race_ethnicity_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'mode_type',
summarize_by = c('race', 'ethnicity'),
summarize_vartype = 'categorical',
weighted = TRUE,
wtname = 'trip_weight',
se = TRUE)
head(mode_by_race_ethnicity_summary$summary$wtd, 10)## race ethnicity
## <fctr> <fctr>
## 1: African American or Black Not of Hispanic, Latino, or Spanish origin
## 2: African American or Black Not of Hispanic, Latino, or Spanish origin
## 3: African American or Black Not of Hispanic, Latino, or Spanish origin
## 4: African American or Black Not of Hispanic, Latino, or Spanish origin
## 5: African American or Black Not of Hispanic, Latino, or Spanish origin
## 6: African American or Black Not of Hispanic, Latino, or Spanish origin
## 7: African American or Black Not of Hispanic, Latino, or Spanish origin
## 8: African American or Black Not of Hispanic, Latino, or Spanish origin
## 9: African American or Black Another Hispanic, Latino, or Spanish origin
## 10: African American or Black Another Hispanic, Latino, or Spanish origin
## mode_type count prop prop_se est est_se
## <int> <int> <num> <num> <num> <num>
## 1: 1 143 0.395021634 0.028786577 75777 7152.8334
## 2: 3 4 0.012990669 0.006892942 2492 1331.4537
## 3: 4 1 0.002424021 0.002422381 465 465.0000
## 4: 6 1 0.004514414 0.004501905 866 866.0000
## 5: 7 1 0.002429234 0.002427578 466 466.0000
## 6: 8 173 0.418427775 0.028683214 80267 7061.2787
## 7: 11 3 0.004550904 0.002717711 873 521.1549
## 8: 13 53 0.159641349 0.021778953 30624 4566.8926
## 9: 1 2 0.270056497 0.179646281 956 696.6059
## 10: 8 4 0.729943503 0.179646281 2584 1413.9469Calculating trip rates
hts_summary can also be used to calculate trip
rates.
DT = hts_prep_triprate(summarize_by = 'employment',
variables_dt = variable_list,
trip_name = 'trip',
day_name = 'day',
hts_data = list('hh' = hh,
'person' = person,
'day' = day,
'trip' = trip,
'vehicle' = vehicle))
trip_rate_by_employment_summary = hts_summary(prepped_dt = DT$num,
summarize_var = 'num_trips_wtd',
summarize_by = 'employment',
summarize_vartype = 'numeric',
weighted = TRUE,
wtname = 'day_weight',
se = TRUE)
head(trip_rate_by_employment_summary$summary$wtd, 10)## employment count min max mean mean_se median
## <int> <int> <num> <num> <num> <num> <num>
## 1: 1 1858 0 62.56075 3.770511 0.08744228 2.562929
## 2: 2 333 0 49.51000 4.518665 0.26799833 3.027821
## 3: 3 251 0 63.59574 3.750584 0.25813849 2.478788
## 4: 5 1000 0 59.23973 3.394865 0.12525765 2.021469
## 5: 6 164 0 45.62069 3.144907 0.26774656 2.197662
## 6: 7 52 0 32.36364 4.070054 0.56907009 2.720099
## 7: 8 14 0 21.92248 2.728166 0.92991111 0.904000
## 8: 995 513 0 58.78947 2.098985 0.10435428 1.272311Labeling Values
To label values we can use factorize_column.
trip_rate_by_employment_summary$summary$wtd$employment = factorize_column(
trip_rate_by_employment_summary$summary$wtd$employment,
'employment',
value_labels,
variable_colname = 'variable',
value_colname = 'value',
value_label_colname = 'label',
value_order_colname = 'val_order'
)
trip_rate_by_employment_summary$summary$wtd## employment
## <ord>
## 1: Employed full-time (35+ hours/week, paid)
## 2: Employed part-time (fewer than 35 hours/week, paid)
## 3: Self-employed
## 4: Not employed and not looking for work (e.g., retired, stay-at-home parent, student)
## 5: Unemployed and looking for work
## 6: Unpaid volunteer or intern
## 7: Employed, but not currently working (e.g., on leave, furloughed 100%)
## 8: Missing Response
## count min max mean mean_se median
## <int> <num> <num> <num> <num> <num>
## 1: 1858 0 62.56075 3.770511 0.08744228 2.562929
## 2: 333 0 49.51000 4.518665 0.26799833 3.027821
## 3: 251 0 63.59574 3.750584 0.25813849 2.478788
## 4: 1000 0 59.23973 3.394865 0.12525765 2.021469
## 5: 164 0 45.62069 3.144907 0.26774656 2.197662
## 6: 52 0 32.36364 4.070054 0.56907009 2.720099
## 7: 14 0 21.92248 2.728166 0.92991111 0.904000
## 8: 513 0 58.78947 2.098985 0.10435428 1.272311Creating Visuals using hts_summary output
hts_summary creates outputs that can easily be used to
create visuals.
## Warning: package 'ggplot2' was built under R version 4.3.2
p = ggplot(
trip_rate_by_employment_summary$summary$wtd,
aes(x = mean, y = employment)) +
geom_bar(stat = 'identity') +
geom_errorbar(
aes(xmin = (mean - mean_se),
xmax = (mean + mean_se),
width = .2)
) +
labs(x = 'Mean Trip Rate',
y = 'Employment') +
scale_y_discrete(labels = function(x) stringr::str_wrap(x, width = 50),
limits = rev)
print(p)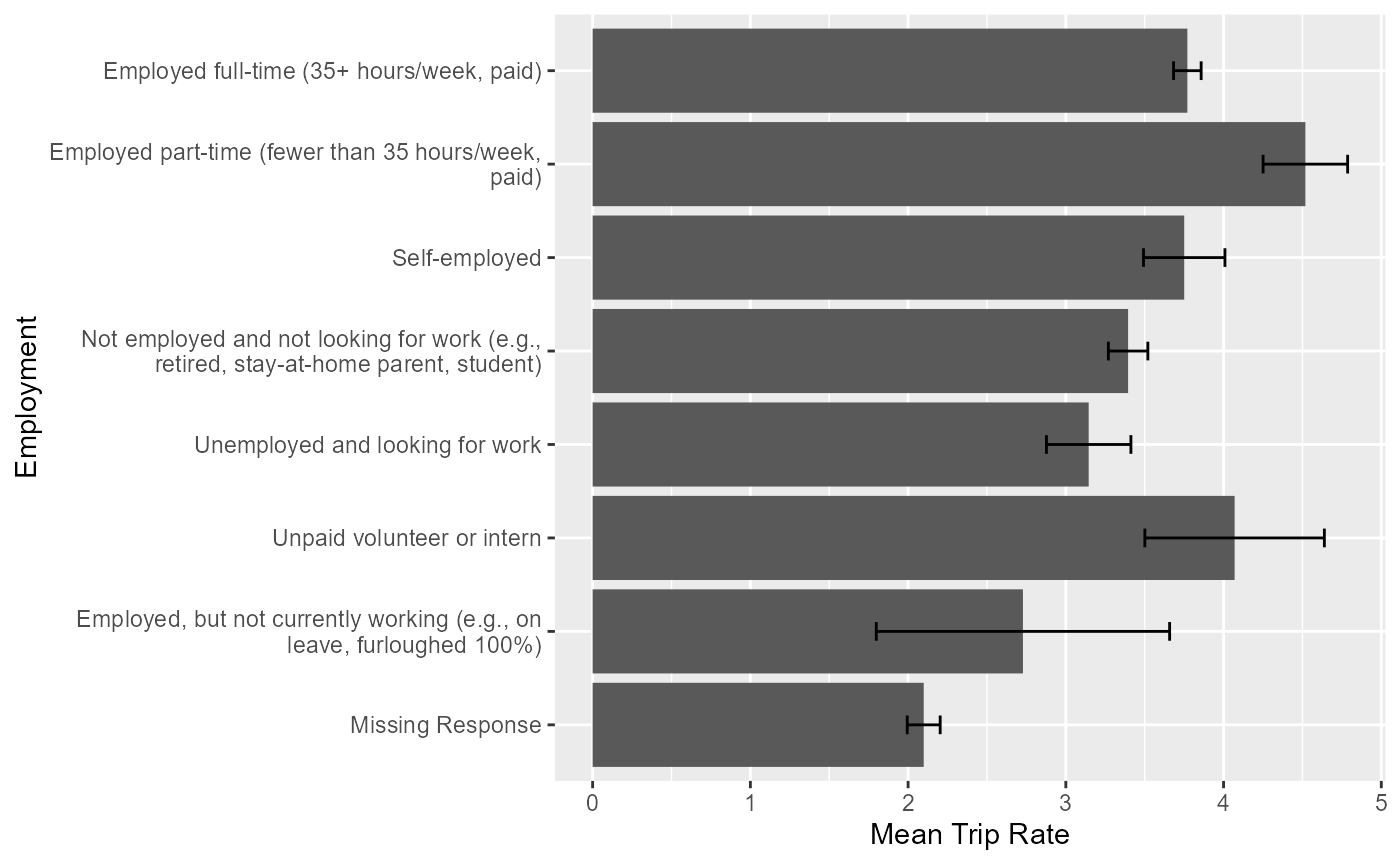
Summarizing a new variable
To summarize a new variable with hts_summary it must
first be added to the variable_list and
value_labels. In this example we are creating a new
variable called hh_size that we want to summarize.
test_data$hh[, hh_size := ifelse(num_people < 4, 0, 1)]
variable_list = rbind(variable_list,
data.table(variable = 'hh_size',
is_checkbox = 0,
hh = 1,
person = 0,
day = 0,
trip = 0,
vehicle = 0,
description = 'Household size',
data_type = 'integer/categorical',
shared_name = 'hh_size')
)
value_labels = rbind(value_labels,
data.table(variable = rep('hh_size', 2),
value = c(0,1),
label = c('Small household', 'Large household'),
val_order = c(214:215))
)
DT = hts_prep_data(summarize_var = 'hh_size',
variables_dt = variable_list,
data = test_data)
hh_size_summary = hts_summary(prepped_dt = DT$cat,
summarize_var = 'hh_size',
summarize_vartype = 'categorical',
weighted = TRUE,
wtname = 'hh_weight')
factorize_df(df = hh_size_summary$summary$wtd, value_labels, value_label_colname = 'label')## hh_size count prop est
## <ord> <int> <num> <int>
## 1: Small household 881 0.8786678 448161
## 2: Large household 119 0.1213322 61885