# Load hts.weighting Package
devtools::load_all()
# Load Settings; Pass python_env Explicitly for Quarto
settings = get_settings(reload_settings = TRUE,
print = FALSE)
# Set Pathways for Reference
code_root = get("code_root", settings)
work_dir = get('working_dir', settings)
inputs_dir = get('inputs_dir', settings)
outputs_dir = get('outputs_dir', settings)
report_dir = get('report_dir', settings)
popsim_initial_label = get("popsim_initial_label", settings)
popsim_daypat_label = get("popsim_daypat_label", settings)10 Round 3 Weighting: Trip Weight Adjustments
10.1 Overview
In the previous chapter, Round 2 household-level weights were produced, adjusting for day-pattern response bias. This script will start by using those weights to produce person- and day-level weights. These weights are applied to the trip table to generate unlinked (and, if available, linked trip and tour) trip weights. However, analysis of other household travel surveys has shown that the number of trips reported varies systematically by diary platform. To correct for this bias, this script applies a final stage of adjustment at the trip level, referred to as Round 3 weighting.
10.2 Chapter Setup
10.3 Calculate Round 2 Person-, Day-, and Trip-Level Weights
After Round 2 household-level weights are generated from PopulationSim, person- and day-level weights are calculated, and from this point foreward receive no further adjustments. These weights are then used to calculate the Round 2 unlinked and, if available, linked trip- and tour-level weights.
Key Concept: How Are Person-, Day-, and Unlinked Trip-Level Weights Calculated?
- Person-level weights: Each person is assigned their corresponding household-level weight for each weighted day group (
weight_dow_groups) specified in the settings. If adjustment for unrelated household members is specified in the settings, their weights are set to 0 and the remaining household members have their weights adjusted up. - Day-level weights: The day weight is calculated as the person weight divided by the number of completed days in the household. Days that are not study days (i.e., not in specified day-of-week groups) and/or are incomplete are assigned a weight of 0.
- Unlinked trip-level weights: Each unlinked trip is assigned their corresponding day weight. Unlinked trips that occurred on non-study days are set to 0. Synthetically produced trips are assigned a weight of 0 if
weight_synthetic_tripsin the settings is set to false.
PSRC Specifics
- Day-of-week weights were not calculated for PSRC, so the day-level weight represents one average weekday for each person in the study. Thus, the sum of the trip-level weight represents the total trips in the region on an average weekday (Tuesday, Wednesday, and Thursday)./
- Synthetic trips were not weighted.
Key Concept: Linked Trip and Tour Weights
Linked trip and tour weights represent the average weight of their component trips (linked trips) or legs (tours). Linked trip weights are the average of the weighted unlinked trips that make up that linked trip.
# Load Imputed Household and Person Data, Along with Survey Tables.
households = readRDS(file.path(work_dir, 'households_survey_imputed.rds'))
persons = readRDS(file.path(work_dir, 'persons_survey_imputed.rds'))
# Get Codebook and Other Survey Tables for Value Labels, Days, and Trips
value_labels = fetch_hts_table('value_labels', settings)
days = fetch_hts_table("day", settings)
trips = fetch_hts_table("trip", settings)
# Remove any Records Associated with Dropped Households to Ensure Data Consistency
persons = persons[hh_id %in% households$hh_id]
days = days[hh_id %in% households$hh_id]
trips = trips[hh_id %in% households$hh_id]
# Organize Weighting Rounds and Prepare to Collect Output Weights for Diagnostics
popsim_rounds = list(
round_1 = get('popsim_initial_label', settings),
round_2 = get('popsim_daypat_label', settings)
)
weights_list = list()
# This Prepares a Set of Weights for Each Weighting Round, for Diagnostic Purposes.
for (round_type in names(popsim_rounds)) {
if (
round_type == "round_2" &&
! get('daypat_weighting', settings)
) {
message(paste0("Skipping ", round_type, " weights as 070_daypat_weighting.R was not run."))
next
}
hh_weights_path = file.path(
get('working_dir', settings),
popsim_rounds[[round_type]],
'output/final_summary_hh_weights.csv'
)
hh_weights_raw = fread(hh_weights_path, colClasses = c(hh_id_dow = 'character'))
setnames(hh_weights_raw, 'zone_group_balanced_weight', 'hh_weight')
# Add num_trips to days -------------------------------------------------------
if (!("num_trips" %in% names(days))) {
days[
trips[, .N, keyby = .(day_id)],
num_trips := i.N,
on = .(day_id)
]
days[is.na(num_trips), num_trips := 0]
}
# Check that hh_num_weekdays_complete is correct
# Otherwise, weight totals will not match
hh_complete_days = calc_complete_hhdays(households, days, settings, include_zeros = TRUE)
# If only one day_group, remove dummy nonstudy_day
if (length(get("weight_dow_groups", settings)) == 1) {
hh_complete_days = hh_complete_days[day_group != 'nonstudy_day', ]
}
hh_weights = merge(
hh_weights_raw,
hh_complete_days[, .(hh_id_dow, n_complete_hh_days, diary_platform, day_group, hh_id)],
by = "hh_id_dow",
all = TRUE
)
hh_weights[is.na(hh_weight), hh_weight := 0]
# Recalculate number of complete person days for each day_group
day_groups = get_day_groups(settings)
days[, person_id := as.character(person_id)]
days[day_groups, day_group := i.day_group, on = .(travel_dow)]
days[, n_complete_person_days := 0]
days[is_complete == 1, n_complete_person_days := .N, by = .(person_id, day_group)]
# All Online diaries should only have one complete day
stopifnot(hh_weights[diary_platform != "rmove" & n_complete_hh_days != 1, .N] == 0)
# Sum of weights should not change
stopifnot(hh_weights[hh_weight > 0, .N] == hh_weights_raw[, .N])
# Calculate person weights -----------------------------------------------------
hh_weights[households, `:=`
(
num_people = i.num_people,
num_adults = i.num_adults
),
on = .(hh_id)
]
person_weights = calc_person_weights(
hh_weights,
households,
persons,
value_labels,
settings
)
# Calculate day weights -------------------------------------------------------
# days[, person_id := as.character(person_id)] # Can we delete this line?
day_weights = calc_day_weights(
person_weights,
households,
persons,
days,
trips,
value_labels,
settings
)
# Trip weights =================================================================
trip_weights = calc_trip_weights(trips, day_weights, settings)
# Cross-check for missing relationships, set to 0 if orphaned ------------------
# Find common day_ids in days, trips
common_day_ids = intersect(days$day_id, trips$day_id)
common_person_ids = intersect(intersect(persons$person_id, days$person_id), trips$person_id)
# Check for orphaned trips that don't have a day or person or household
# This should not happen, but if it does, set the weight to 0
trip_weights[
!day_id %in% common_day_ids |
!hh_id %in% households$hh_id |
!person_id %in% common_person_ids,
trip_weight := 0
]
# If person level study, adjust the hh_weights by num_adults since the hh_weight is the person weight
if (get("study_unit", settings) == "person") {
hh_weights[, hh_weight := hh_weight / num_adults]
}
# Append to output weights -----------------------------------------------------
weights_round = list(
hh_weights = hh_weights[, .(hh_id, day_group, hh_weight)],
person_weights = person_weights[, .(hh_id, person_id, day_group, person_weight)],
day_weights = day_weights[, .(hh_id, person_id, day_id, day_group, day_weight)],
trip_weights = trip_weights[,
.(hh_id, person_id, day_id, trip_id, linked_trip_id, tour_id, day_group, trip_weight)
]
)
# Check that all nonstudy_day day_groups are 0 weight
for (wt in weights_round) {
wt_col = stringr::str_subset(names(wt), "weight$")
if (wt[day_group == "nonstudy_day", sum(get(wt_col))] != 0) {
stop(paste0("Nonstudy day group has non-zero weight in ", wt_col, " column."))
}
}
# Linked trip and tour weights =================================================
if ("linked_trip" %in% names(settings$hts_table_map)) {
# Load linked trips
linked_trips = fetch_hts_table("linked_trip", settings)
# Filter out records for dropped households
linked_trips = linked_trips[linked_trip_id %in% unique(trips$linked_trip_id), ]
# Assign day_group
linked_trips[day_weights, day_group := i.day_group, on = .(day_id)]
stopifnot(all(!is.na(linked_trips$day_group)))
# Calculate linked trip weights
linked_trip_weights = calc_linked_trip_weights(
linked_trips,
unlinked_trips = trips,
unlinked_trip_weights = trip_weights,
day_weights,
settings
)
# Append to output
weights_round[['linked_trip_weights']] = linked_trip_weights[,
.(hh_id, person_id, day_id, linked_trip_id, tour_id, day_group, linked_trip_weight)
]
}
if ("tour" %in% names(settings$hts_table_map)) {
# Load tour data
tours = fetch_hts_table("tour", settings)
# Assign day_group
linked_trips[day_weights, day_group := i.day_group, on = .(day_id)]
stopifnot(all(!is.na(linked_trips$day_group)))
# Filter out records for dropped households
tours = tours[tour_id %in% unique(linked_trips$tour_id), ]
# Calculate tour weights
tour_weights = calc_tour_weights(
tours,
unlinked_trips = trips,
unlinked_trip_weights = trip_weights,
day_weights,
settings
)
# Append to output
weights_round[['tour_weights']] = tour_weights[,
.(hh_id, person_id, day_id, tour_id, day_group, tour_weight)
]
}
weights_list[[round_type]] = weights_round
}Save Round 2 Person-, Day-, and Trip-Level Weights
# Append Weights with Suffix and Write to CSV ==============================================
# Unsuffixed Weight is the "Current" Weight with the Adjustments from the Latest Round
appended_weights_list = list()
for (round_name in names(weights_list)) {
weights_round = weights_list[[round_name]]
message(paste0("Appending weights from round: ", round_name))
for (table_name in names(weights_round)) {
# First round, just copy
if (is.null(appended_weights_list[[table_name]])) {
weight_comb = copy(weights_round[[table_name]])
# Copy current weight to a suffixed column
wt_col = stringr::str_subset(names(weight_comb), '_weight$')
wt_col_adj = paste0(wt_col, '_', round_name)
weight_comb[, (wt_col_adj) := get(wt_col)]
} else {
weight_prev = appended_weights_list[[table_name]]
id_cols = c(
stringr::str_subset(names(weight_prev), '_id$'),
"day_group"
)
weight_comb = merge(
weight_prev,
weights_round[[table_name]],
by = id_cols,
suffixes = c('', paste0('_', round_name)),
all = TRUE
)
# Updated canonical weight to the latest round
wt_col = stringr::str_subset(names(weight_prev), '_weight$')
wt_col_adj = paste0(wt_col, '_', round_name)
weight_comb[, (wt_col) := get(wt_col_adj)]
}
# Check that the canonical weight matches the latest suffixed weight
stopifnot(all(weight_comb[[wt_col]] == weight_comb[[wt_col_adj]], na.rm = TRUE))
# Update the combined weight table
appended_weights_list[[table_name]] = weight_comb
}
}
# Write Out Combined Weights for Reference
for (weight_table in names(appended_weights_list)) {
path = file.path(get('outputs_dir', settings), paste0(weight_table, '.csv'))
message(paste0('Writing combined ', weight_table, ' to ', path))
fwrite(appended_weights_list[[weight_table]], file = path)
}
# Save a Dummy File to Indicate 080 has Run
write.table(
"This is placeholder text. This file is used track the pipeline outputs.",
file.path(get('working_dir', settings), ".unadjusted_weights"),
row.names = FALSE, col.names = FALSE, quote = FALSE
)10.4 Round 3 Weighting
Overview
Analyses of other RSG household travel surveys show that the number of trips reported varies systematically by diary platform. In particular, Online and Call Center respondents tend to under-report certain types of trips compared to respondents using the rMove smartphone app, which automatically records travel in the background. To correct for this bias, RSG adjusts trip-level weights using calculated correction factors, referred to as Round 3 weighting.
The adjustment procedure operates at the linked trip level, unless linked trips are unavailable in which case unlinked trips are used. Each linked trip is classified into a mutually exclusive trip type, and trip rate factors are then estimated and applied to linked trips. Unlinked trips and tours receive their weights from linked trips. To ensure that the adjustment models have sufficient sample size, produce stable factors across person types and diary platforms, and yield interpretable results, this process estimates trip adjustment models for broader classes of trip purposes rather than for each survey-reported purpose category. Using origin and destination purposes, linked trips were classified into 4 categories (work, school, other, and loop). Only trips eligible for that trip type (i.e., work trips among employed persons) are considered for trip bias adjustment.
Round 3 Weighting: What You’ll Do
- Filter out unweighted records from each dataset.
- Categorize each linked trip (or if unavailable, unlinked trip) into mutually exclusive groups using the survey-reported trip purpose.
- Calculate the number of trips (overall and by trip type) for each person-day.
- Prepare the person-day dataset for modelling by assigning household- and person-level characteristics to each observation, which will serve as model covariates.
- Estimate Poisson regression models for each trip type, predicting the number of trips per person-day.
- Calculate correction factors by trip type by comparing predictions with and without diary platform coefficients.
- Adjust eligible trips using correction factors.
- If linked trip data are used in the steps above, calculate unlinked trip and tour weights using the new Round 3 adjusted weight.
- Review model fit/coefficients and trip rates by diary platform across each round of weighting for quality assurance.
In development
Trip weight adjustment is actively under development. Planned updates are improvement in model fit by testing different model types and applying adjustments in PopulationSim. The goal of this work is to update models for accuracy and to not separate weight adjustments from the PopulationSim adjustment procedures.
Clean and Prepare Data
This section prepares the survey data by filtering out records without valid weights. Then, the number of unweighted trips per day using only weighted records, and weight variables are reset to the most recent round of weighting. For day-of-week weights, an average point estimate is generated for the household and person across survey days. The reset weights are then joined to the survey data, and diary platform information is appended to the unlinked trip weights to ensure consistency and readiness for subsequent analyses.
Load Data
Load the household, person, day, and trip survey datasets and weights.
# Load Value Labels and Imputed HTS Data for Households, Persons, Days, and Trips
value_labels = fetch_hts_table('value_labels', settings)
# Load HTS Data with Imputations
households_raw = readRDS(file.path(work_dir, 'households_survey_imputed.rds'))
persons_raw = readRDS(file.path(work_dir, 'persons_survey_imputed.rds'))
days_raw = fetch_hts_table("day", settings)
trips_raw = fetch_hts_table("trip", settings)
# Set up Column Classes for Joining and Reading weights
colclasses = c(
hh_id = 'character',
person_id = 'character',
day_id = 'character',
trip_id = 'character',
linked_trip_id = 'character',
tour_id = 'character'
)
# Load the Round 2 Weights ------
hh_weights = fread(
file.path(get('outputs_dir', settings), 'hh_weights.csv'),
colClasses = colclasses[c('hh_id')]
)
person_weights = fread(
file.path(get('outputs_dir', settings), 'person_weights.csv'),
colClasses = colclasses[c('hh_id', 'person_id')]
)
day_weights = fread(
file.path(get('outputs_dir', settings), 'day_weights.csv'),
colClasses = colclasses[c('hh_id', 'person_id', 'day_id')]
)
header = names(fread(file.path(get('outputs_dir', settings), 'trip_weights.csv'), nrows = 0))
trip_weights = fread(
file.path(get('outputs_dir', settings), 'trip_weights.csv'),
colClasses = colclasses[intersect(names(colclasses), header)]
)Filter Out Unweighted Records
Remove households and associated data with zero weights from all relevant datasets, ensuring only records with valid weights are retained.
# Find Hh's with All Zero Weight Days
zero_wt_hhs = hh_weights[, sum(hh_weight), by = hh_id][V1 == 0, hh_id]
# Drop All Unweighted Data
households = households_raw[!hh_id %in% zero_wt_hhs]
persons = persons_raw[person_id %in% person_weights[person_weight > 0, person_id]]
days = days_raw[day_id %in% day_weights[day_weight > 0, day_id]]
trips = trips_raw[trip_id %in% trip_weights[trip_weight > 0, trip_id]]Recalculate Number of Trips in Day Table from Trip Table
Ensure that the number of trips in the day table reflects only weighted trips for consistency.
# Recalculate num_trips in Day Table from Trip Table to Ensure Consistency ------
days[
trips[, .(num_trips = .N), by = .(day_id)],
num_trips := i.num_trips,
on = .(day_id)
]
day_weights[days, num_trips := i.num_trips, on = "day_id"]
day_weights[is.na(num_trips), num_trips := 0]Reset Trip Weight to Previous Weighting Round and Drop All Dummy Weights
Reset trip weights to their most recent round of weighting, removing outdated or dummy weight columns, and verify weight sums for data integrity.
# Reset Canonical Trip Weight to Latest Non-Adjusted Trip Weight (e.g., Round 1 or 2) ----
if ("trip_weight_round_3" %in% names(trip_weights)) {
trip_weights[, trip_weight_round_3 := NULL]
}
if ('trip_weight_round_2' %in% names(trip_weights)) {
trip_weights[, trip_weight := trip_weight_round_2]
} else {
trip_weights[, trip_weight := trip_weight_round_1]
}
# Check that we Didn't Drop Something we Should Have
stopifnot(
all.equal(
day_weights[, sum(day_weight * num_trips)],
trip_weights[, sum(trip_weight)]
)
)
# Drop Dummy Integer Weights from Survey Tables -------------------------------
for (tbl_name in list("households", "persons", "days", "trips")) {
dt = get(tbl_name)
wt_col = grep('_weight$', names(dt), value = TRUE)
if (length(wt_col) > 1) {
stop("Multiple weight columns found in table ", tbl_name)
} else if (length(wt_col) == 1) {
dt[, (wt_col) := NULL]
}
}Calculate a Point Estimate Weight for Households/Persons Across Days
Compute average weights for households and persons across all days to provide point estimates for further analysis. If only one average weight across all days was calculated, the calculated weight will be the same.
# Calculate a Point Estimate Weight for Households and Persons across Days
hh_weights_avg = hh_weights[, .(hh_weight = mean(hh_weight)), by = .(hh_id)]
person_weights_avg = person_weights[, .(person_weight = mean(person_weight)), by = .(person_id)]Join Weights to Survey Data
Attach the weights to their respective household, person, day, and trip tables based on unique identifiers.
# Join the Weights to their Respective Tables using Appropriate Keys
households[hh_weights_avg, hh_weight := i.hh_weight, on = "hh_id"]
persons[person_weights_avg, person_weight := i.person_weight, on = "person_id"]
days[day_weights, day_weight := i.day_weight, on = "day_id"]
trips[trip_weights, trip_weight := i.trip_weight, on = "trip_id"]Append Diary Platform Information to Trip Weights
Adds diary platform details to trip weights to support adjustment modeling.
# Add Diary Platform Information to Trip Weights for Adjustment Modeling
trip_weights[households, diary_platform := i.diary_platform, on = "hh_id"]Trip Type Assignment
Trips are classified using the reported origin and destination purposes in the survey data into four mutually exclusive categories:
Work: trips with one end at work or a work-related location.
School: trips with one end at school or a school-related location.
Other: all other trips excluding loop trips.
Loop: trips that start and end in the same location.
Loop trips are identified in the linked trip table but excluded from the adjustment procedures. Loop trips are typically made for walking the dog or exercising and are not typically modeled. They also tend to be represented more in rMove data than in other survey modes and therefore would obfuscate the trip adjustment procedure if included.
Prepare Trip Types Table
This section creates a table for trip type assignment, using linked trip data if available. The table is limited to just the variables needed for trip type assignment.
# Prepare Trip Types Table, Using Linked Trips if Available, Otherwise use Unlinked Trips
if ("linked_trip" %in% names(settings$hts_table_map)) {
linked_trips = fetch_hts_table("linked_trip", settings)
idcols = stringr::str_subset(
names(fread(file.path(get('outputs_dir', settings), 'linked_trip_weights.csv'), nrows = 1)),
"(.+)_id$"
)
# Same logic, if this is a re-run read in all rounds of weights.
linked_trip_weights = fread(
file.path(get('outputs_dir', settings), 'linked_trip_weights.csv'),
colClasses = setNames(rep('character', length(idcols)), idcols)
)
# Limit to weighted households only
linked_trips = linked_trips[hh_id %in% households$hh_id]
# Create table for trip type assignment
trips_types = copy(
linked_trips[, .(
hh_id,
linked_trip_id,
day_id,
person_id,
opcat = o_purpose_category,
dpcat = d_purpose_category
)
]
)
join_col = "linked_trip_id"
# Join linked trip ID to trip weights
trip_weights[trips_raw, linked_trip_id := i.linked_trip_id, on = "trip_id"]
# Join linked trip weight and day group to trip types table
trips_types[linked_trip_weights, `:=`(
trip_weight = i.linked_trip_weight,
day_group = i.day_group
), on = "linked_trip_id"]
# Reset canonical linked trip weight to latest non-adjusted trip weight (e.g., daypat or initial) ----
if ("linked_trip_weight_round_3" %in% names(linked_trip_weights)) {
linked_trip_weights[, linked_trip_weight_round_3 := NULL]
}
if ('linked_trip_weight_round_2' %in% names(linked_trip_weights)) {
linked_trip_weights[, linked_trip_weight := linked_trip_weight_round_2]
} else {
linked_trip_weights[, linked_trip_weight := linked_trip_weight_round_1]
}
# Limit to weighted linked trips only
linked_trips = linked_trips[linked_trip_id %in% linked_trip_weights[linked_trip_weight > 0, linked_trip_id]]
} else {
# Make a copy of trips for the trip types table
trips_types = copy(
trips_raw[, .(
hh_id, trip_id, day_id, person_id,
opcat = o_purpose_category,
dpcat = d_purpose_category
)
]
)
join_col = "trip_id"
trips_types[trip_weights, `:=`(
trip_weight = i.trip_weight,
day_group = i.day_group
), on = "trip_id"]
}Categorize and Assign Trip Types
This step categorizes each trip into an aggregated trip type category based on its origin and destination purposes. This process ensures all trips receive an appropriate type, aggregates results as defined in settings, and merges trip type assignments back to the main trips table.
# Assign Trip Types to Trip Table
label_dt = value_labels[variable == "d_purpose_category", .(value, label = str_to_lower(label))]
pcat_work = label_dt[str_detect(label, "work"), value]
pcat_school = label_dt[str_detect(label, "school"), value]
pcat_home = label_dt[str_detect(label, "home"), value]
pcat_loop = 14L
# Identify Loop Trip IDs in Trips Table
measure_id = 'trip_id'
if ("linked_trip" %in% names(settings$hts_table_map)) measure_id = 'linked_trip_id'
loop_trip_ids = trips_raw[split_loop == 1 | split_loop_leg == 1, get(measure_id)]
# Assign Trip Type to Each Trip
trips_types[, trip_type_detailed := fcase(
get(measure_id) %in% loop_trip_ids, "num_loop",
(dpcat %in% pcat_loop), "num_loop",
(opcat %in% pcat_home) & (dpcat %in% pcat_work), "num_work",
(dpcat %in% pcat_home) & (opcat %in% pcat_work), "num_work",
(opcat %in% pcat_home) & (dpcat %in% pcat_school), "num_school",
(dpcat %in% pcat_home) & (opcat %in% pcat_school), "num_school",
(opcat %in% pcat_home) & !(dpcat %in% c(pcat_work, pcat_school)), "num_other",
(dpcat %in% pcat_home) & !(opcat %in% c(pcat_work, pcat_school)), "num_other",
!(opcat %in% pcat_home) & (dpcat %in% pcat_work), "num_work",
!(dpcat %in% pcat_home) & (opcat %in% pcat_work), "num_work",
!(opcat %in% pcat_home) & (dpcat %in% pcat_school), "num_school",
!(dpcat %in% pcat_home) & (opcat %in% pcat_school), "num_school",
!(opcat %in% pcat_home) & !(dpcat %in% c(pcat_work, pcat_school)), "num_other",
!(dpcat %in% pcat_home) & !(opcat %in% c(pcat_work, pcat_school)), "num_other"
)]
# Assign Trip Types to the trips_types Table, Aggregate as Specified in Settings
model_lhs = get("trip_rate_model_lhs", settings)
for (var in names(model_lhs)) {
subtypes = if (is.null(model_lhs[[var]])) var else model_lhs[[var]]
trips_types[trip_type_detailed %in% subtypes, trip_type := var]
}
# Check for NA
stopifnot(trips_types[is.na(trip_type_detailed), .N] == 0)
# Merge trips_types Back onto linked_trips Table and Weights
linked_trips[trips_types, trip_type := i.trip_type, on = "linked_trip_id"]
# Add in Diary Platform to trips_types Table
trips_types[households, diary_platform := diary_platform, on = "hh_id"]
# For Consistency, Limit Trip Types Data to Complete Weighted Observations
if ("linked_trip" %in% names(settings$hts_table_map)) {
trips_types = trips_types[linked_trip_id %in% linked_trip_weights[linked_trip_weight > 0, linked_trip_id] &
hh_id %in% households$hh_id]
} else {
trips_types = trips_types[trip_id %in% trip_weights[trip_weight > 0, trip_id] &
hh_id %in% households$hh_id]
}Re-Calculate Number of Trips by Person-Day
This step calculates the number of trips for each person on weighted complete travel days. The day-level data is limited to completed weighted day observations and diary platform is appended to the dataset. The number of trips per day is then recalculated using the categorized trips table. Since the number of trips per day is calculated from the categorized trips table, missing observations for num_trips occur when there are no trips and thus are relabelled to 0s. The datasets are then saved for future reference in QAQC outputs.
# Get Complete Days and Day of Week
complete_days = days[
hh_day_complete == 1 & travel_dow %in% unlist(get("weight_dow_groups", settings)),
.(hh_id, person_id, day_id, travel_dow, num_trips, day_weight)
]
complete_days[get_day_groups(settings), day_group := i.day_group, on = "travel_dow"]
# Add in Diary Platform to complete_days Table
complete_days[households, diary_platform := diary_platform, on = "hh_id"]
# Filter Complete Weekdays
trips_types_complete = trips_types[day_id %in% complete_days[, day_id], ]
n_trips = nrow(trips_types_complete)
# Recalculate the Effective Number of Trips per Day from Trips Table
# This Means Using Linked Trips when Available, so it Might be Different from num_trips in Days Table
complete_days[
trips_types[, .N, by = .(day_id)],
num_trips := i.N,
on = .(day_id)
]
# Fill NAs with Zeros for No Trips
setnafill(complete_days, cols = c("num_trips"), fill = 0)
# Write Datasets to Working Directory for Future Reference
fwrite(trips_types_complete,
file.path(get("working_dir", settings), "trip_types_complete.csv"))
fwrite(complete_days,
file.path(get("working_dir", settings), "day_complete_days.csv"))Prepare Data for Modelling
This step constructs a modeling dataset for each trip type containing the number of trips per person-day, filtered to those person-day records from eligible person-types. Eligibility criteria are determined using household- and person-level characteristics and appended to the person-day dataset here.
The eligibility criteria for trip weight adjustment is defined by trip type below:
Work trips: Adults who are employed full- or part-time.
School trips: Children who are proxy reported.
Other trips: All adults.
These eligibility rules define the subset of person-days that enter the trip rate models. Only the trip records associated with eligible person-type × trip-type combinations are used in estimation; and only eligible person-type × trip-type combinations receive adjustments. The majority of school trips are proxy-reported trips for children, so adults who report school trips are excluded. This is because that model would make different assumptions and the sample size of adults making school trips tends to be too low to produce stable estimates. In some cases, respondents may record a trip to work or school even when they do not report themselves as a student or employee. In these cases, the person’s signup survey information (employment status, student status) is prioritized over the person’s travel diary information, and trip adjustment procedures are restricted to the logical categories of people who should receive them. Trips made by those under 18 were not eligible for work and other trip adjustment.
This step also creates and appends the independent variables incorporated into the trip adjustment models. These models include independent variables that might affect how the type of diary people use relates to the number of trips they report. Daily trip rates serve as the dependent variables in the adjustment models.
PSRC Specifics
Due to small sample size of Call Center participants, Call Center and Online diary platform responses were combined into one category for modelling and trip weight adjustment.
Independent variables, their categorization, and reference categories for each model can be found in the table below.
| Variable | Categories | Work model | School model | Other model |
|---|---|---|---|---|
| Diary platform |
|
☓ | ☓ | ☓ |
| Household size |
|
☓ | ☓ | ☓ |
| Number of kids in HH |
|
☓ | ☓ | |
| Household income |
|
☓ | ☓ | ☓ |
| Employment status |
|
☓ | ☓ | |
| Works from home |
|
☓ | ☓ | |
| Age |
|
☓ | ☓ | |
| Student status |
|
☓ | ☓ | |
| Work location regularly varies |
|
☓ | ||
| Educational attainment |
|
☓ | ☓ | |
| Proxy reporter’s employment status |
|
☓ | ||
| Proxy reporter works from home |
|
☓ | ||
| Proxy reporter’s gender |
|
☓ | ||
| Current school level |
|
☓ |
## Pivot Trip Dataset to be Day-Level for Merging
trip_type_counts = dcast(
trips_types_complete[, .N, by = .(day_id, person_id, trip_type)],
day_id ~ trip_type,
value.var = "N",
fill = 0
)
## For Merge Make Sure id is Character
trip_type_counts[, day_id := as.character(day_id)]
complete_days[, day_id := as.character(day_id)]
## Add "num_" Prefix to Column Names of trip_type_counts
renamees = names(trip_type_counts)["day_id" != names(trip_type_counts)]
setnames(trip_type_counts, old = renamees, new = paste0("num_", renamees))
## Now Merge that Onto Complete Weekdays, Filling Days with no Observations as 0 Trips
trip_counts = merge(
complete_days,
trip_type_counts,
by = "day_id", all.x = TRUE
)
setnafill(trip_counts, cols = str_subset(names(trip_counts), "num_"), fill = 0)
# Some QAQC
trip_type_cols = paste0("num_", trips_types_complete[, unique(trip_type)])
trip_counts[, rowsums := rowSums(.SD), .SDcols = trip_type_cols]
stopifnot(trip_counts[num_trips != rowsums, .N] == 0)
# Write Dataset to Folder
fwrite(trip_counts,
file.path(get("working_dir", settings), "trip_counts.csv"))Create Household-Level Model Variables
## Household-Level Variables for Models-----------------------------------------
households <- as.data.table(households)
# Household Size
households[, hh_size := fcase(
num_people == 1, 1,
num_people == 2, 2,
num_people >= 3, 3,
default = NA
)]
# Number of Kids in HH
households[, n_kids := fcase(
num_kids == 0, 0, # 0
num_kids >= 1, 1, # 1+
default = NA
)]
# Income Categorized Further
households[, income_cat := fcase(
income_imputed %in% c(1,2), 1, # Under $49,999k
income_imputed %in% c(3,4), 2, # $50k - $99,999k
income_imputed %in% c(5,6), 3, # Above $100k
default = NA
)]
# Merge Household Variables into Model Data ------------------------------------
fit_dt = merge(
trip_counts,
households[, .(
hh_id, hh_size, n_kids,
income_imputed, income_imputed_label, income_cat
)],
by = "hh_id",
all.x = TRUE # Drop households with no trips. They probably didn't have complete days
)Create Person-Level Model Variables
# Person-Level Variables for Models --------------------------------------------
persons <- as.data.table(persons)
# Adults
persons[, is_adult := fcase(
age > 3, 1,
age <= 3, 0,
default = NA
)]
# Employment Status
persons[, employment_status := fcase(
paid_work == 0 | employment == 5, 0, # Unemployed
paid_work %in% c(1,2) & employment %in% c(1, 3) , 1, # Full-time
paid_work %in% c(1,2) & employment %in% c(2, 8), 2, # Part-time
paid_work == 995, NA,
default = 0
)]
## If Under 16, Count as Unemployed
persons[age < 3, employment_status := 0]
# Work from Home
persons[employment_status %in% c(1,2), wfh := fcase(
work_from_home == 0, 3, # Never
work_from_home == 3, 1, # Always
work_from_home %in% c(1,2), 2, # Hybrid
default = NA
)]
# If Unemployed, Count as Never Works from Home
persons[employment_status == 0, wfh := 3]
# Age Categorized
persons[, age_cat_adults := fcase(
age < 4, 0, # Under 18
age == 4, 1, # 18-24
age %in% c(5, 6, 7, 8), 2, # 25-64
age > 8, 3, # 65+
default = NA
)]
# Educational Attainment
persons[, education_cat := fcase(
education %in% c(1,2,4), 1, # Less than/Completed high school/Vocational training
education == 3, 2, # Some college
education %in% c(5,6), 3, # Bachelor's/Associate's degree
education == 7, 4, # Graduate degree
default = NA
)]
# Student Status
persons[, is_student := fcase(
student %in% c(0, 1, 3, 4), 1, # Current student (adult)
student == 2, 0, # Not a student (adult)
default = NA
)]
# Work Location Varies
persons[employment_status %in% c(1, 2), work_loc_varies := fcase(
wfh == 1, 0, # works from home, does not vary
wfh != 1 & job_type %in% c(2,3), 1, # Work location varies/delivery driver
wfh != 1 & job_type == 1, 0, # Work location does not vary
default = NA
)]
persons[employment_status == 0, work_loc_varies := 0]
# School Type
persons[, school_cat := fcase(
age < 4 & school_type %in% c(1, 4), 1, # Home schooled/cared for at home
age < 4 & school_type == 2, 2, # Pre-k/daycare,
age < 4 & school_type %in% c(5, 6), 3, # Elementary/Middle school
age < 4 & school_type == 7, 4, # High-school/Vocational training
age >= 3 & school_type %in% c(7, 10), 4, # High-school/Vocational training
age >= 3 & school_type %in% c(11,13), 5, # Bachelor's/Associate's/Graduate
age >= 3 & is_student == 0, 0, # Not in school
default = NA
)]
# Add in Student Status for those Under 18
persons[age < 4, is_student := fcase(
school_cat %in% c(2, 3, 4, 5), 1,
school_cat == 1, 0,
default = NA
)]
# Separate Proxy Reporters and Create Proxy Reporter Variables for School Models
kp <- persons[is_proxy == 1]
kp[, `:=`(
p_employment = employment_status,
p_wfh = wfh,
p_gender = gender_imputed
)]
# Use Household ID to Link Proxy Reporter Information to Persons who were Proxy-Reported
# in that household
persons[kp, `:=`(
p_employment = i.p_employment,
p_wfh = i.p_wfh,
p_gender = i.p_gender
), on = "hh_id"]
# Merge Person Variables into Model Data ---------------------------------------
fit_dt = merge(
fit_dt,
persons[,
.(
person_id, is_adult, employment_status, wfh,
age_cat_adults, education_cat, is_student, work_loc_varies,
school_cat, p_employment, p_wfh, p_gender, has_proxy
)],
by = "person_id",
all.x = TRUE
)Create Trip Model Estimation Weights
This step calculates estimation weights for model fitting by scaling each record’s day weight relative to the average day weight, ensuring the total weights match the number of observations.
Purpose of the Estimation Weight
Estimation weights are used in Poisson regression to adjust for differing probabilities of selection or representation in the sample, making the model’s parameter estimates more reflective of the target population. Scaling ensures comparability and proper influence of each record in the model fitting process.
# Estimation Weights -----------------------------------------------------------
# Scale the Day Weight to the Dataset for Models
fit_dt[, estimation_weight := day_weight / mean(day_weight)]
stopifnot(all.equal(fit_dt[, sum(estimation_weight)], nrow(fit_dt)))Configure Variables for Models
To ensure the models are estimated correctly with easily understood outputs, this step converts each variable to a factor variable and explicitly defines the categorical levels.
# Factor Vars for Model --------------------------------------------------------
# Diary Platform as a Binary Variable for Model
fit_dt[, diary_binary := fcase(
diary_platform %in% c("browser", "call"), "online/call",
default = diary_platform
)]
# For the Models, Make Variables Factors and Add Labels; Some Extras in Here for
# Testing with Expanded Categories
fit_dt[, `:=`(
diary_platform = factor(diary_platform,
levels = c("rmove", "browser", "call"),
ordered = FALSE),
diary_binary = factor(diary_binary,
levels = c("rmove", "online/call"),
ordered = FALSE),
hh_size = factor(hh_size,
levels = c(1, 2, 3),
labels = c("1", "2", "3+"),
ordered = FALSE),
n_kids = factor(n_kids,
levels = c(0, 1),
labels = c("0", "1+"),
ordered = FALSE),
income_imputed = factor(income_imputed,
levels = c(1,2,3,4,5,6),
labels = c("$0-$24,999", "$25,000-$49,999", "$50,000-$74,999",
"$75,000-$99,999", "$100,000-$199,999", "$200,000+"),
ordered = FALSE),
employment_status = factor(employment_status,
levels = c(0,1,2),
labels = c("Unemployed", "Full-time", "Part-time"),
ordered = FALSE),
wfh = factor(wfh,
levels = c(1,2,3),
labels = c("Always", "Hybrid", "Never"),
ordered = FALSE),
age_cat_adults = factor(age_cat_adults,
levels = c(0,1,2,3),
labels = c("Under 18","18-24", "25-64", "65+"),
ordered = FALSE),
education_cat = factor(education_cat,
levels = c(1,2,3,4),
labels = c("Less than/Completed high school/Vocational training",
"Some college", "Bachelor's/Associate's degree", "Graduate degree"),
ordered = FALSE),
is_student = factor(is_student,
levels = c(0, 1),
labels = c("Not a student", "Student"),
ordered = FALSE),
work_loc_varies = factor(work_loc_varies,
levels = c(0, 1),
labels = c("No", "Yes"),
ordered = FALSE),
income_cat = factor(income_cat,
levels = c(1, 2, 3),
labels = c("Under $50k", "$50-$100k", "Above $100k"),
ordered = FALSE),
school_cat = factor(school_cat,
levels = c(0, 1, 2, 3, 4, 5),
labels = c("Not in school", "Home schooled/cared for at home", "Pre-k/Daycare",
"Elementary/Middle school", "High-school/Vocational training", "Bachelor's/Associate's/Graduate"),
ordered = FALSE),
p_employment = factor(p_employment,
levels = c(0,1,2),
labels = c("Unemployed", "Full-time", "Part-time"),
ordered = FALSE),
p_wfh = factor(p_wfh,
levels = c(1,2,3),
labels = c("Always", "Hybrid", "Never"),
ordered = FALSE),
p_gender = factor(p_gender,
levels = c("male", "female"),
labels = c("Male", "Female"),
ordered = FALSE)
)]Review Sample Size for Models
To ensure that model sample size is sufficient, review the number of person-days, adjustment-eligible trips, and total trips for each trip type (Work, School, Other, Total) across different diary platforms. This breakdown helps ensure sufficient data across platforms and trip categories, as well as the correct assignment of trip adjustment eligibility and trip categories before fitting models.
The table below outlines the number of person-days, adjustment eligible trips, and total trips by trip type and diary platform. This information outlines the number of trips eligible for adjustment for bias with respect to the total number of trips.
Trip type | Diary platform | Person-days | Adjustment-eligible trips | Total trips |
|---|---|---|---|---|
Other | Online | 4,255 | 8,048 | 8,826 |
Call Center | 155 | 361 | 373 | |
rMove | 2,297 | 5,215 | 5,474 | |
All platforms | 6,707 | 13,624 | 14,673 | |
School | Online | 683 | 1,040 | 1,215 |
Call Center | 9 | 14 | 16 | |
rMove | 179 | 251 | 368 | |
All platforms | 871 | 1,305 | 1,599 | |
Work | Online | 2,343 | 3,003 | 3,185 |
Call Center | 48 | 59 | 63 | |
rMove | 1,549 | 2,689 | 2,816 | |
All platforms | 3,940 | 5,751 | 6,064 | |
Total | Online | 4,938 | 12,091 | 13,578 |
Call Center | 164 | 434 | 462 | |
rMove | 2,476 | 8,155 | 9,337 | |
All platforms | 7,578 | 20,680 | 23,377 |
Prepare Model Formulas
Lastly, the variables for each model formula are read in from the settings. This enables code to be efficient and dynamic in producing models.
# Right-Hand Side of Formula
model_rhs_vars = get("trip_rate_model_vars", settings)
model_lhs = get("trip_rate_model_lhs", settings)
# Left-Hand Side of Formula
model_lhs_num = paste(paste0("num_", names(model_lhs)))Estimate Models
This step estimates the trip adjustment Poisson regression models that predict the number of trips of each type per person-day. The dependent variables are trip counts by type (e.g., number of work trips). Model fit statistics are also calculated for QAQC.
model_ls = list()
trip_rate_factors_all = fit_dt[, .(hh_id, person_id, day_id, diary_binary)]
for (lhs in model_lhs_num) {
if (lhs == "num_loop") next
model_rhs_num = model_rhs_vars[[lhs]]
model_rhs = paste("~", paste(model_rhs_num, collapse = " + "))
# Build formula from the remaining terms
fmla = as.formula(paste(lhs, model_rhs))
cli::cli_inform(c("model formula: ", fmla))
# TODO: parameterize
# Restrict to appropriate sub-populations
if (lhs %like% 'work') {fit_dt_est = fit_dt[is_adult == 1 & employment_status %in% c("Full-time", "Part-time")]
} else if (lhs %like% 'school') {fit_dt_est = fit_dt[is_adult == 0 & has_proxy == 1]
} else if (lhs %like% 'other') {fit_dt_est = fit_dt[is_adult == 1]
}
# Estimate model
model = glm(
fmla,
data = fit_dt_est,
weights = fit_dt_est[, estimation_weight],
family = "poisson"
)
model_ls[[lhs]] = model
model_desc = broom::tidy(model)
# Prepare model results
model_perf = as.data.table(performance::model_performance(model))
r2 = t(model_perf)[, 1][grepl("R2", names(model_perf))]
range = paste(paste(c('low:', 'high:'), round(range(fitted(model)), 4)), collapse = ", ")
report_dir = get('report_dir', settings)
model_name = gsub("num_", "model_", lhs)
# Save model
fwrite(model_desc, file.path(report_dir, "models", paste0(model_name, "_coef.csv")))
fwrite(model_perf, file.path(report_dir, "models", paste0(model_name, "_fit.csv")))
}Review Trip Weight Adjustment Models
The results of the trip rate adjustment models are shown in the tables below. P-values for individual variables may not always be significant, but the variables are retained in the model for estimation purposes. McFadden’s R2 is also presented below each table to represent the model fit.
Variable | Estimate | Std Error | T-Statistic | p.value |
|---|---|---|---|---|
Model intercept | 1.115 | 0.071 | 15.70 | <0.001 |
-0.377 | 0.024 | -15.95 | <0.001 | |
HH size: 2 (Ref: 1) | -0.064 | 0.031 | -2.08 | 0.037 |
HH size: 3+ (Ref: 1) | -0.007 | 0.037 | -0.19 | 0.845 |
HH income: $50-$100k (Ref: Under $50k) | 0.036 | 0.030 | 1.17 | 0.242 |
HH income: Above $100k (Ref: Under $50k) | -0.109 | 0.029 | -3.74 | <0.001 |
1+ kids in HH (Ref: no kids) | 0.415 | 0.028 | 14.68 | <0.001 |
Employment status: Full-time (Ref: Unemployed or Part-time) | -0.771 | 0.027 | -28.12 | <0.001 |
Employment status: Part-time (Ref: Unemployed) | -0.378 | 0.030 | -12.49 | <0.001 |
Works from home: Hybrid (Ref: Always) | -0.251 | 0.040 | -6.34 | <0.001 |
Works from home: Never (Ref: Always) | -0.384 | 0.039 | -9.94 | <0.001 |
Age: 25-64 (Ref: 18-24) | 0.399 | 0.046 | 8.65 | <0.001 |
Age: 65+ (Ref: 18-24) | 0.418 | 0.051 | 8.19 | <0.001 |
Student (Ref: Not student) | -0.131 | 0.045 | -2.90 | 0.004 |
Education: Some college (Ref: Less than/complete high school/Vocational training) | 0.240 | 0.035 | 6.87 | <0.001 |
Education: Bachelor's/Associate's (Ref: Less than/complete high school/Vocational training) | 0.268 | 0.028 | 9.73 | <0.001 |
Education: Graduate degree (Ref: Less than/complete high school/Vocational training) | 0.382 | 0.030 | 12.59 | <0.001 |
McFadden's rho-squared: 0.303 | ||||
Variable | Estimate | Std Error | T-Statistic | p.value |
|---|---|---|---|---|
Model intercept | -3.561 | 0.467 | -7.62 | <0.001 |
0.127 | 0.058 | 2.20 | 0.028 | |
HH size: 3+ (Ref: 1) | -0.466 | 0.137 | -3.39 | <0.001 |
HH income: $50-$100k (Ref: Under $50k) | 0.228 | 0.105 | 2.16 | 0.031 |
HH income: Above $100k (Ref: Under $50k) | 0.506 | 0.098 | 5.17 | <0.001 |
School level: Pre-k/Daycare (Ref: Home-schooled/cared for at home) | 4.430 | 0.436 | 10.16 | <0.001 |
School level: Elementary/Middle school (Ref: Home-schooled/cared for at home) | 4.454 | 0.434 | 10.25 | <0.001 |
School level: High-school/Vocational training (Ref: Home-school/cared for at home | 4.499 | 0.436 | 10.33 | <0.001 |
School level: Bachelor's/Associate's/Graduate degree (Ref: Home-school/cared for at home | 1.983 | 1.206 | 1.65 | 0.1 |
Proxy employment status: Full-time (Ref: Unemployed) | -0.288 | 0.057 | -5.03 | <0.001 |
Employment status: Part-time (Ref: Unemployed) | -0.229 | 0.070 | -3.26 | 0.001 |
Proxy works from home: Hybrid (Ref: Always) | -0.093 | 0.102 | -0.91 | 0.361 |
Proxy works from home: Never (Ref: Always) | -0.166 | 0.101 | -1.64 | 0.102 |
Proxy gender: Female (Ref: Male) | -0.040 | 0.046 | -0.87 | 0.385 |
McFadden's rho-squared: 0.708 | ||||
Variable | Estimate | Std Error | T-Statistic | p.value |
|---|---|---|---|---|
Model intercept | -1.526 | 0.154 | -9.90 | <0.001 |
-0.423 | 0.031 | -13.81 | <0.001 | |
HH size: 2 (Ref: 1) | -0.078 | 0.041 | -1.94 | 0.053 |
HH size: 3+ (Ref: 1) | -0.103 | 0.051 | -2.03 | 0.042 |
HH income: $50-$100k (Ref: Under $50k) | 0.096 | 0.045 | 2.12 | 0.034 |
HH income: Above $100k (Ref: Under $50k) | 0.003 | 0.043 | 0.07 | 0.942 |
1+ kids in HH (Ref: no kids) | 0.015 | 0.040 | 0.37 | 0.71 |
Employment status: Part-time (Ref: Unemployed) | -0.233 | 0.035 | -6.66 | <0.001 |
Works from home: Hybrid (Ref: Always) | 2.403 | 0.138 | 17.37 | <0.001 |
Works from home: Never (Ref: Always) | 2.598 | 0.138 | 18.85 | <0.001 |
Age: 25-64 (Ref: 18-24) | 0.117 | 0.055 | 2.13 | 0.034 |
Age: 65+ (Ref: 18-24) | 0.046 | 0.077 | 0.60 | 0.546 |
Student (Ref: Not student) | 0.102 | 0.064 | 1.60 | 0.11 |
Work location varies regularly (Ref: Does not vary regurlarly) | 0.327 | 0.028 | 11.67 | <0.001 |
Education: Some college (Ref: Less than/complete high school/Vocational training) | -0.494 | 0.056 | -8.87 | <0.001 |
Education: Bachelor's/Associate's (Ref: Less than/complete high school/Vocational training) | -0.160 | 0.034 | -4.76 | <0.001 |
Education: Graduate degree (Ref: Less than/complete high school/Vocational training) | -0.219 | 0.038 | -5.75 | <0.001 |
McFadden's rho-squared: 0.388 | ||||
Calculate Trip Weight Adjustment Factors
To isolate the effect of trip diary bias, and calculate bias adjustment factors, two sets of predictions are produced for each model:
With diary platform coefficients included, reflecting observed differences between platforms.
With diary platform coefficients set to zero, removing platform effects.
The ratio of these two predictions represent the modeled trip rate adjustment factor (see “Modeled” column). For example, if the model predicted 1.10 trips with diary platform effects and 1.32 without them, the resulting adjustment factor was 1.20 (1.32 ÷ 1.10).
Because rMove is specified as the reference platform, its modeled factor is always 1.0.
Calculate Initial Adjustment Factors from Models
# Calculate Trip Weight Adjustment Factors =====================================
trip_rate_factors_all = fit_dt[, .(hh_id, person_id, day_id, diary_binary)]
for (lhs in model_lhs_num) {
if (lhs == "num_loop") next
model = model_ls[[lhs]]
# Restrict to appropriate sub-populations
if (lhs %like% 'work') {fit_dt_est = fit_dt[is_adult == 1 & employment_status %in% c("Full-time", "Part-time")]
} else if (lhs %like% 'school') {fit_dt_est = fit_dt[is_adult == 0 & has_proxy == 1]
}else if (lhs %like% 'other') fit_dt_est = fit_dt[is_adult == 1]
bias_vars = stringr::str_subset(all.vars(formula(model)), "^diary_*")
bias_vars = paste(bias_vars[bias_vars != "diary_rmove"], collapse = "|")
model_coefs = coef(model)
bias_idx = which(str_detect(names(model_coefs), bias_vars))
# Make copy and set bias coefficients to 0
model_corrected = model
model_corrected$coefficients[bias_idx] = 0
# Make trip count predictions
fit_dt_est[, pred := predict(model, newdata = fit_dt_est, type = "response")]
fit_dt_est[, pred_corrected := predict(model_corrected, newdata = fit_dt_est, type = "response")]
# Calculate trip rate factor
fit_dt_est[, trip_rate_factor := pred_corrected / pred]
fit_dt_est[, .N, keyby = .(diary_binary, round(trip_rate_factor, 2))]
# Clean up
response_var = all.vars(formula(model))[1]
newname = str_replace(response_var, "num", "trip_rate_factor")
setnames(fit_dt_est, "trip_rate_factor", newname)
# Save individual factors
rate_factor_name_i = names(fit_dt_est)[names(fit_dt_est) %like% 'trip_rate_factor']
factor_cols = c(
"hh_id", "person_id", "day_id", "diary_binary",
# names(trip_rate_factors_all),
rate_factor_name_i
)
factors_i = fit_dt_est[, .SD, .SDcols = factor_cols]
# Join, fill missing
trip_rate_factors_all = merge(
trip_rate_factors_all,
factors_i,
by = c("hh_id", "person_id", "day_id", "diary_binary"),
all.x = TRUE
)
setnafill(trip_rate_factors_all, "const", fill = 1.0, cols = rate_factor_name_i)
}
#fit_dt_est = merge(
fit_dt_all = merge(
fit_dt,
trip_rate_factors_all,
by = c("hh_id", "person_id", "day_id", "diary_binary"), #"day_group"),
all.x = TRUE
)Rescale and Cap Adjustment Factors
After the first calculation, the modeled factors are rescaled so that the minimum factor for each trip type is set to 1.0. This step enforces the working assumption that platform differences reflect under-reporting rather than over-reporting: if a platform’s raw factor fell below 1.0, that value is reset to 1.0 and all other platform factors are scaled upward relative to it. As a result, rMove’s factor could remain at 1.0 or increase above 1.0, depending on the relative positioning of other platforms. To avoid extreme corrections, factors are then capped at 2.0.
trip_rate_cols = grep("trip_rate_factor_", names(fit_dt_all), value = TRUE)
# Make a Dataset with Just the ids and Factors
estimate_dt_all = copy(
fit_dt_all[, mget(c("hh_id", "person_id", "day_id", "diary_binary", trip_rate_cols))]
)
# Melt Dataset for Reporting Trip Adjustment Factors by Diary Platform and Trip Type
rate_factor_dt = data.table::melt(
estimate_dt_all[, c("diary_binary", trip_rate_cols), with = FALSE],
measure.vars = trip_rate_cols,
id.vars = 'diary_binary',
variable.name = 'trip_type',
value.name = 'factor'
)
# Make Factor Column Names Just the Trip Type
rate_factor_dt[, trip_type := stringr::str_replace(trip_type, 'trip_rate_factor_', '')]
# Remove Duplicate Factors
raw_factors = dcast(rate_factor_dt[(diary_binary == "online/call" & factor != 1) | diary_binary == "rmove"],
diary_binary ~ trip_type,
value.var = "factor",
fun.aggregate = mean, na.rm = TRUE)
modelled_factors = dcast(rate_factor_dt[(diary_binary == "online/call" & factor != 1) | diary_binary == "rmove"],
trip_type ~ diary_binary,
value.var = "factor",
fun.aggregate = mean, na.rm = TRUE)
# Rescale the Factors if rMove if not the Minimum Factor
weight_adj_dt = rate_factor_dt
weight_adj_dt[, ref_factor := min(factor, na.rm=TRUE), by = .(trip_type)]
weight_adj_dt[, rescaled_factor := factor / ref_factor]
# Reshape Back to Original Format
rescaled_factors = dcast(weight_adj_dt[(diary_binary == "online/call" & factor != 1) | diary_binary == "rmove"],
trip_type ~ diary_binary,
value.var = "rescaled_factor",
fun.aggregate = mean, na.rm = TRUE )
hard_cap = 2.0 # Default Hard Cap for Trip Rate Factors
if ("trip_rate_factor_cap" %in% names(settings)) {
hard_cap = as.numeric(settings$trip_rate_factor_cap)
}
# Cap Any Factors over 2
capped_factors = copy(rescaled_factors)
capped_factors[`online/call` > 2, `online/call` := 2]Export Adjustment Factors
# Combine into One Dataset
all_factors <- rbindlist(list("modeled" = modelled_factors,
"rescaled" = rescaled_factors,
"capped" = capped_factors),
idcol = "processing_step")
all_factors <- melt(all_factors, id.vars = c("processing_step", "trip_type"),
value.name = "factor", variable.name = "platform")
all_factors <- dcast(all_factors, trip_type + platform ~ processing_step)
setcolorder(all_factors, c("trip_type", "platform", "modeled", "rescaled", "capped"))
all_factors[, platform := factor(platform, levels = c("online/call", "rmove"))]
all_factors[, trip_type := factor(trip_type, levels = c("other", "school", "work"))]
setorderv(all_factors, c("trip_type", "platform"))
# Write Dataset for Reporting
fwrite(all_factors, file.path(settings$report_dir, "models", "trip_adjustment_factors.csv"))Review Adjustment Factors
Trip type | Diary platform | Modeled | Rescaled | Capped |
|---|---|---|---|---|
Other | Online/Call Center | 1.46 | 1.46 | 1.46 |
rMove | 1.00 | 1.00 | 1.00 | |
School | Online/Call Center | 0.88 | 1.00 | 1.00 |
rMove | 1.00 | 1.14 | 1.14 | |
Work | Online/Call Center | 1.53 | 1.53 | 1.53 |
rMove | 1.00 | 1.00 | 1.00 |
Adjust Weights
Apply Trip Weight Adjustment Factors to Trip Weights
In this step, factors are applied to trip weights produced in Round 2 based on adjustment eligibility and trip type.
# Change Name in Trip Rate Factor Dataset to Match
setnames(all_factors, "platform", "diary_binary", skip_absent = TRUE)
all_factors[, `:=`(
trip_type = as.character(trip_type),
diary_binary = as.character(diary_binary)
)]
# Create Eligibility Variables for Reference and Join to linked_trip_weights
fit_dt_all[, work_eligible := fcase(
employment_status %in% c("Full-time", "Part-time") & is_adult == 1, 1,
default = 0
)]
fit_dt_all[, school_eligible := fcase(
is_adult == 0 & has_proxy == 1, 1,
default = 0
)]
fit_dt_all[, other_eligible := fcase(
is_adult == 1, 1,
default = 0
)]
linked_trip_weights[fit_dt_all, `:=`(
work_eligible = i.work_eligible,
school_eligible = i.school_eligible,
other_eligible = i.other_eligible,
diary_binary = i.diary_binary
), on = c("day_id", "person_id", "hh_id")]
linked_trip_weights[trips_types, trip_type := i.trip_type, on = "linked_trip_id"]
# Join the Trip Rate Factors to the Trip Table for Broad Models
linked_trip_weights[all_factors,
factor := i.capped,
on = c("diary_binary", "trip_type")]
# Apply Factors
linked_trip_weights[trip_type == "work" & work_eligible == 1,
linked_trip_weight_round_3 := linked_trip_weight_round_2 * factor]
linked_trip_weights[trip_type == "work" & is.na(linked_trip_weight_round_3),
linked_trip_weight_round_3 := linked_trip_weight_round_2]
linked_trip_weights[trip_type == "other" & other_eligible == 1,
linked_trip_weight_round_3 := linked_trip_weight_round_2 * factor]
linked_trip_weights[trip_type == "other" & is.na(linked_trip_weight_round_3),
linked_trip_weight_round_3 := linked_trip_weight_round_2]
linked_trip_weights[trip_type == "school" & school_eligible == 1,
linked_trip_weight_round_3 := linked_trip_weight_round_2 * factor]
linked_trip_weights[trip_type == "school" & is.na(linked_trip_weight_round_3),
linked_trip_weight_round_3 := linked_trip_weight_round_2]
linked_trip_weights[trip_type == "loop", linked_trip_weight_round_3 := linked_trip_weight_round_2]
linked_trip_weights[, linked_trip_weight := linked_trip_weight_round_3]
linked_trip_weights[is.na(linked_trip_weight_round_3), linked_trip_weight_round_3 := 0]
fwrite(linked_trip_weights, file.path(settings$outputs_dir, "linked_trip_weights.csv"))
# Export Person-Day Dataset
fwrite(fit_dt_all, file.path(report_dir, "models", paste0("fit_dt_all.csv")))Apply Round 3 Adjusted Linked Trip Weights to Corresponding Unlinked Trips
If linked trips are used to calculate adjustment factors, the adjusted linked trip weights are then mapped back to unlinked trips.
if ("linked_trip" %in% names(settings$weight_output_map)) {
# Unlinked Trip Weights will be the Same as the Linked Trip Weights
# Store as a New Suffixed Column, and as the Canonical trip_weight Column
trip_weights[linked_trip_weights, trip_weight_round_3 := i.linked_trip_weight_round_3, on = 'linked_trip_id']
trip_weights[, trip_weight := trip_weight_round_3]
# Assert no NA Trip Weights
stopifnot(trip_weights[is.na(trip_weight), .N] == 0)
} else {
cat("Skipping this step - linked trip data were not used.")
}Calculate New Tour Weights From Round 3 Adjusted Linked Trip Weights
If linked trips are used to calculate adjustment factors, this step re-calculates tour weights as the mean of the adjusted weights for the linked trips comprising each tour.
# Tour Weights Will be the Mean of the Linked Trip Weights that Make up the Tour
if ("tour" %in% names(settings$weight_output_map)) {
tour_weights = fread(
file.path(get('outputs_dir', settings), 'tour_weights.csv'),
colClasses = colclasses[c("hh_id", "person_id", "day_id", "tour_id")]
)
# Ensure id variables are all character - this sometimes gets reset throughout the process
linked_trip_weights[, `:=`(
hh_id = as.character(hh_id),
person_id = as.character(person_id),
day_id = as.character(day_id),
tour_id = as.character(tour_id)
)]
# Create round 3 variable or set to 0 if a re-run
tour_weights[, tour_weight_round_3 := NA_integer_]
# Calculate new tour weights based on linked trip weights
tour_weights[linked_trip_weights, tour_weight_round_3 :=
mean(linked_trip_weight_round_3[linked_trip_weight_round_3 != 0], na.rm = TRUE),
on = .(hh_id, person_id, day_id, tour_id)]
tour_weights[is.na(tour_weight_round_3), tour_weight_round_3 := 0]
tour_weights[, tour_weight := tour_weight_round_3]
} else {
cat("Skipping this step - either linked trip data were not used and/or tour data are not available.")
}Save Adjusted Weights
# Save Weights =================================================================
weights_output = list(
hh_weights = hh_weights, # Updating to exclude rounds 1-3 columns
person_weights = person_weights, # Updating to exclude rounds 1-3 columns
day_weights = day_weights, # Updating to exclude rounds 1-3 columns
trip_weights = trip_weights
)
# Append Linked Trip Weights if There Are Linked Trips
if ("linked_trip" %in% names(settings$weight_output_map)) {
weights_output[['linked_trip']] = linked_trip_weights
}
# Append Tour Weights if There Are Tours
if ("tour" %in% names(settings$weight_output_map)) {
weights_output[['tour']] = tour_weights
}
# Save Weights
for (wt_table in names(weights_output)) {
path = file.path(get('outputs_dir', settings), paste0(wt_table, '.csv'))
message(paste0('Writing ', wt_table, ' to ', path))
# Drop any column that isn't an ID or a weight column
id_cols = stringr::str_subset(names(weights_output[[wt_table]]), "(.+)_id$")
wt_cols = stringr::str_subset(names(weights_output[[wt_table]]), "(.+)_weight")
factor_cols = stringr::str_subset(names(weights_output[[wt_table]]), "(.+)_factor$")
keep_cols = c("day_group", id_cols, wt_cols, factor_cols)
weights_output[[wt_table]] = weights_output[[wt_table]][, ..keep_cols]
# Order column so the unsuffixed weight column is last
final_col = stringr::str_subset(wt_cols, '_weight$')
wt_order = c(id_cols, setdiff(wt_cols, final_col), final_col)
setcolorder(weights_output[[wt_table]], wt_order)
fwrite(weights_output[[wt_table]], file = path)
}10.5 Review Impact of Round 3 Weight Adjustments on Trip Rates
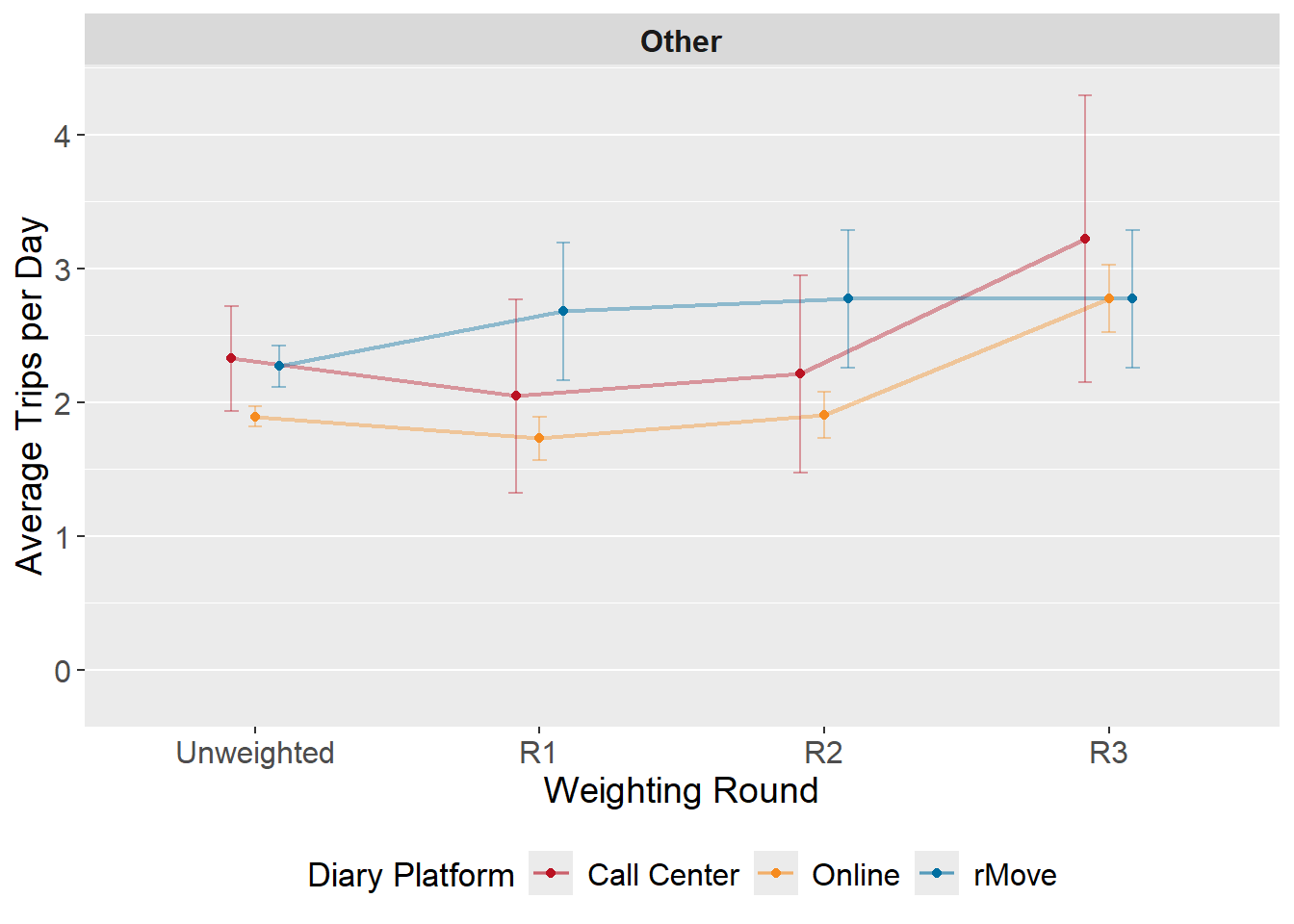
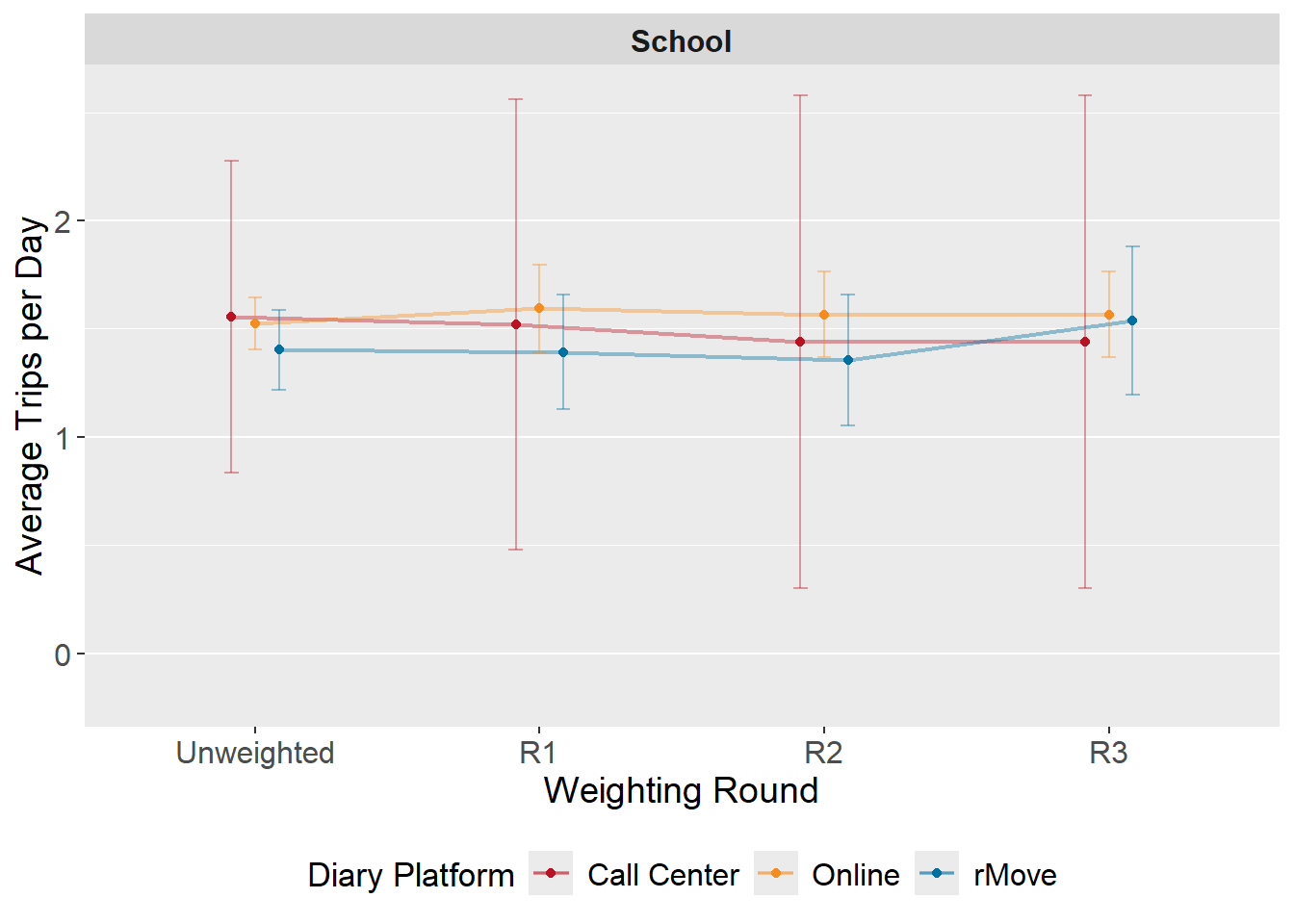
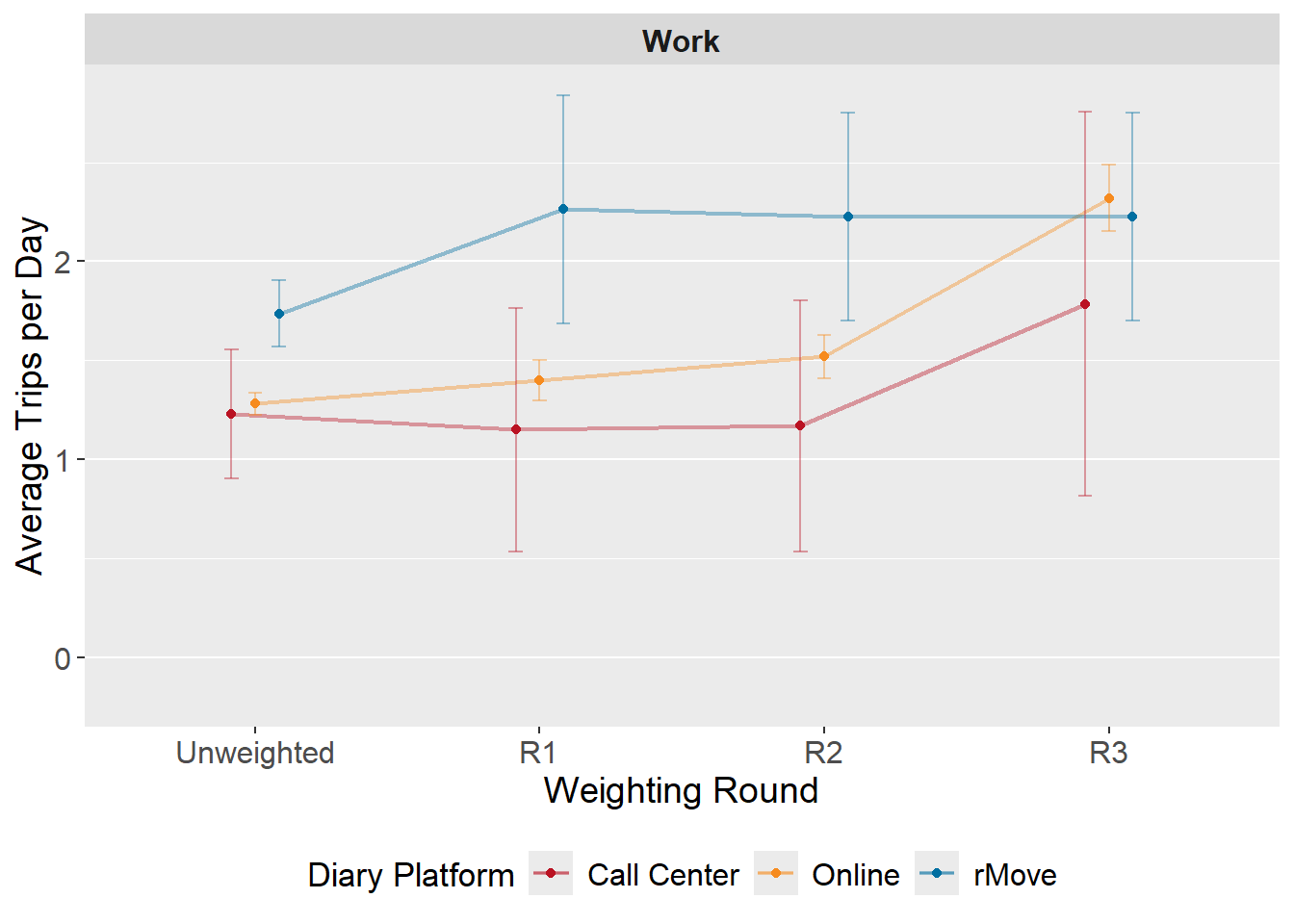
Figure: Trip Rates by Weighting Step and Diary Platform
The below figures summarize how reported trip rates evolve across weighting steps by diary platform. Average daily trip rates are calculated among only those persons eligible for that type of adjustment in Round 3 (i.e., work trip rates are calculated amongst those who are employed). This is done to assess the impact of Round 3 adjustment on trip rate results. Trip rates with large confidence intervals may represent combinations with small sample sizes and should be interpreted with caution.